 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
Paper and Code



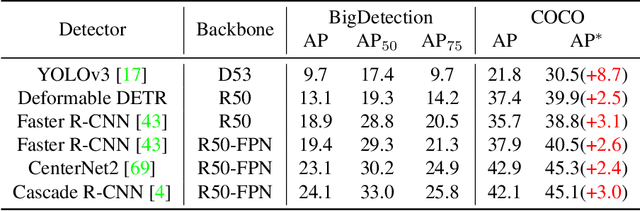
Multiple datasets and open challenges for object detection have been introduced in recent years. To build more general and powerful object detection systems, in this paper, we construct a new large-scale benchmark termed BigDetection. Our goal is to simply leverage the training data from existing datasets (LVIS, OpenImages and Object365) with carefully designed principles, and curate a larger dataset for improved detector pre-training. Specifically, we generate a new taxonomy which unifies the heterogeneous label spaces from different sources. Our BigDetection dataset has 600 object categories and contains over 3.4M training images with 36M bounding boxes. It is much larger in multiple dimensions than previous benchmarks, which offers both opportunities and challenges. Extensive experiments demonstrate its validity as a new benchmark for evaluating different object detection methods, and its effectiveness as a pre-training dataset.