 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Generative Learning Trilemma: Generative Model Assessment in Data Scarcity Domains
Paper and Code
Apr 14, 2025
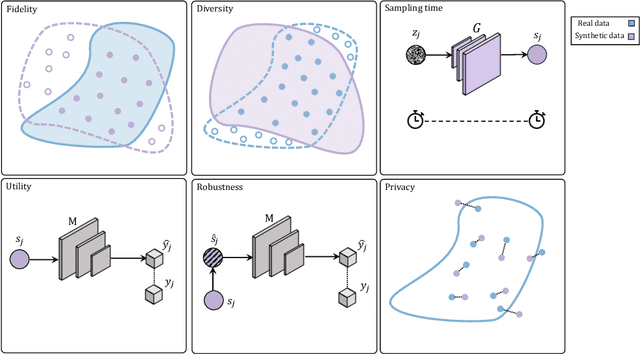
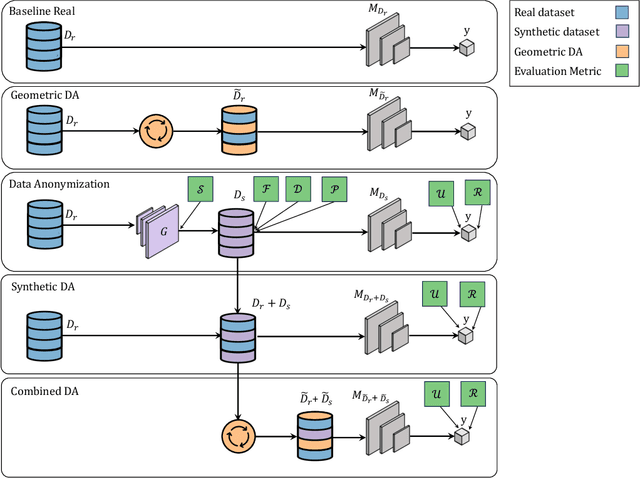
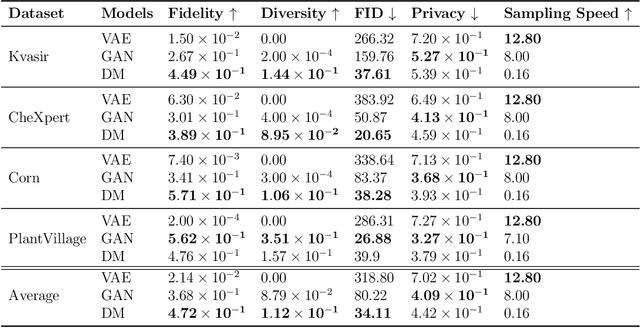
Data scarcity remains a critical bottleneck impeding technological advancements across various domains, including but not limited to medicine and precision agriculture. To address this challenge, we explore the potential of Deep Generative Models (DGMs) in producing synthetic data that satisfies the Generative Learning Trilemma: fidelity, diversity, and sampling efficiency. However, recognizing that these criteria alone are insufficient for practical applications, we extend the trilemma to include utility, robustness, and privacy, factors crucial for ensuring the applicability of DGMs in real-world scenarios. Evaluating these metrics becomes particularly challenging in data-scarce environments, as DGMs traditionally rely on large datasets to perform optimally. This limitation is especially pronounced in domains like medicine and precision agriculture, where ensuring acceptable model performance under data constraints is vital. To address these challenges, we assess the Generative Learning Trilemma in data-scarcity settings using state-of-the-art evaluation metrics, comparing three prominent DGMs: Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Diffusion Models (DMs). Furthermore, we propose a comprehensive framework to assess utility, robustness, and privacy in synthetic data generated by DGMs. Our findings demonstrate varying strengths among DGMs, with each model exhibiting unique advantages based on the application context. This study broadens the scope of the Generative Learning Trilemma, aligning it with real-world demands and providing actionable guidance for selecting DGMs tailored to specific applications.