 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Occam's Razor in System Identification: Double-Descent when Modeling Dynamics
Paper and Code
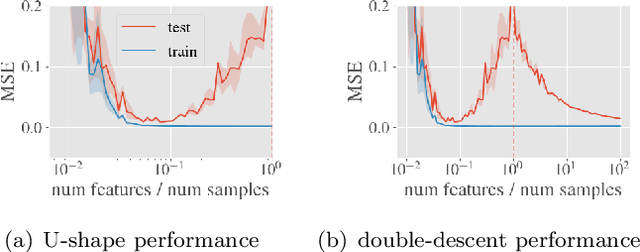
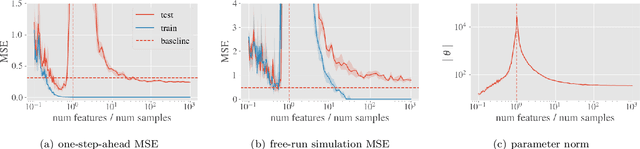
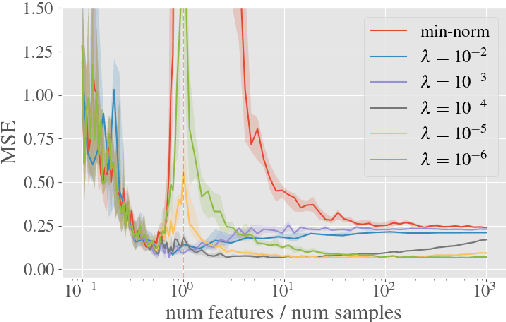
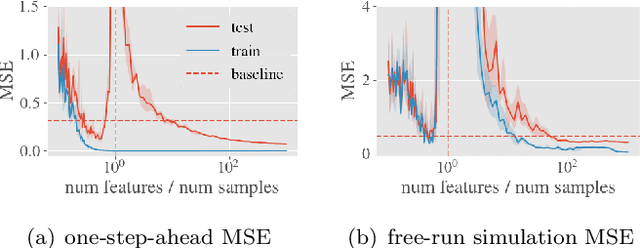
System identification aims to build models of dynamical systems from data. Traditionally, choosing the model requires the designer to balance between two goals of conflicting nature; the model must be rich enough to capture the system dynamics, but not so flexible that it learns spurious random effects from the dataset. It is typically observed that model validation performance follows a U-shaped curve as the model complexity increases. Recent developments in machine learning and statistics, however, have observed situations where a "double-descent" curve subsumes this U-shaped model-performance curve. With a second decrease in performance occurring beyond the point where the model has reached the capacity of interpolating - i.e., (near) perfectly fitting - the training data. To the best of our knowledge, however, such phenomena have not been studied within the context of the identification of dynamic systems. The present paper aims to answer the question: "Can such a phenomenon also be observed when estimating parameters of dynamic systems?" We show the answer is yes, verifying such behavior experimentally both for artificially generated and real-world datasets.