 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Impossibility: Balancing Sufficiency, Separation and Accuracy
Paper and Code
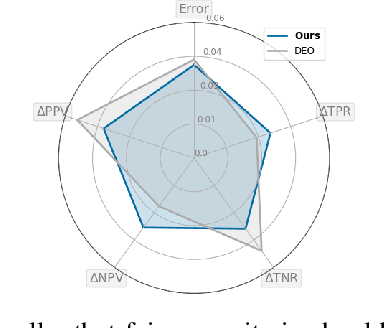

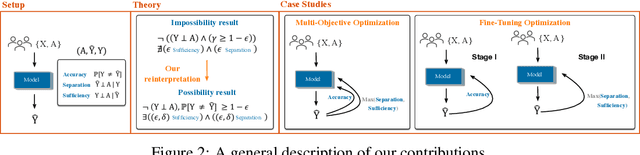
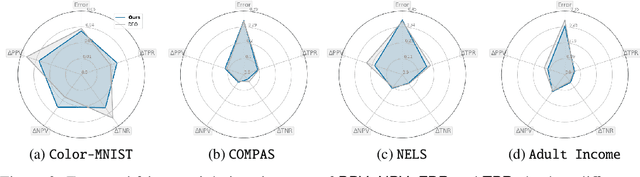
Among the various aspects of algorithmic fairness studied in recent years, the tension between satisfying both \textit{sufficiency} and \textit{separation} -- e.g. the ratios of positive or negative predictive values, and false positive or false negative rates across groups -- has received much attention. Following a debate sparked by COMPAS, a criminal justice predictive system, the academic community has responded by laying out important theoretical understanding, showing that one cannot achieve both with an imperfect predictor when there is no equal distribution of labels across the groups. In this paper, we shed more light on what might be still possible beyond the impossibility -- the existence of a trade-off means we should aim to find a good balance within it. After refining the existing theoretical result, we propose an objective that aims to balance \textit{sufficiency} and \textit{separation} measures, while maintaining similar accuracy levels. We show the use of such an objective in two empirical case studies, one involving a multi-objective framework, and the other fine-tuning of a model pre-trained for accuracy. We show promising results, where better trade-offs are achieved compared to existing alternatives.