 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
Paper and Code
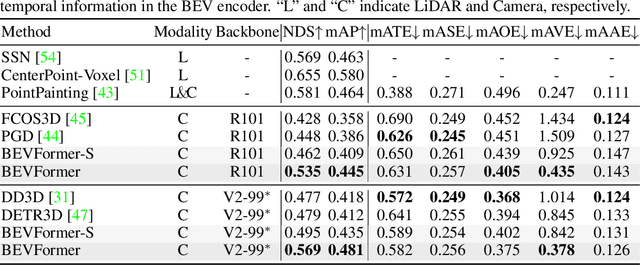
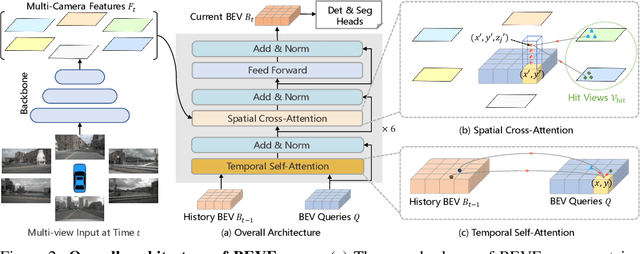
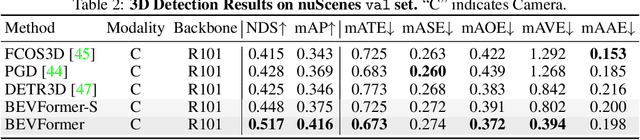
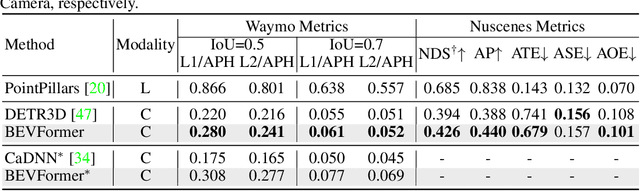
3D visual perception tasks, including 3D detection and map segmentation based on multi-camera images, are essential for autonomous driving systems. In this work, we present a new framework termed BEVFormer, which learns unified BEV representations with spatiotemporal transformers to support multiple autonomous driving perception tasks. In a nutshell, BEVFormer exploits both spatial and temporal information by interacting with spatial and temporal space through predefined grid-shaped BEV queries. To aggregate spatial information, we design a spatial cross-attention that each BEV query extracts the spatial features from the regions of interest across camera views. For temporal information, we propose a temporal self-attention to recurrently fuse the history BEV information. Our approach achieves the new state-of-the-art 56.9\% in terms of NDS metric on the nuScenes test set, which is 9.0 points higher than previous best arts and on par with the performance of LiDAR-based baselines. We further show that BEVFormer remarkably improves the accuracy of velocity estimation and recall of objects under low visibility conditions. The code will be released at https://github.com/zhiqi-li/BEVFormer.