 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTSel: Answer Selection with Pre-trained Models
Paper and Code
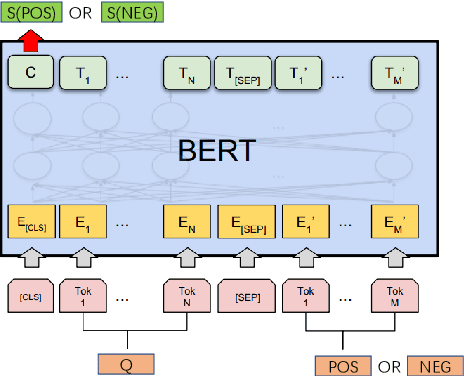



Recently, pre-trained models have been the dominant paradigm in natural language processing. They achieved remarkable state-of-the-art performance across a wide range of related tasks, such as textual entailment, natural language inference, question answering, etc. BERT, proposed by Devlin et.al., has achieved a better marked result in GLUE leaderboard with a deep transformer architecture. Despite its soaring popularity, however, BERT has not yet been applied to answer selection. This task is different from others with a few nuances: first, modeling the relevance and correctness of candidates matters compared to semantic relatedness and syntactic structure; second, the length of an answer may be different from other candidates and questions. In this paper. we are the first to explore the performance of fine-tuning BERT for answer selection. We achieved STOA results across five popular datasets, demonstrating the success of pre-trained models in this task.