 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Optimization Allowing for Common Random Numbers
Paper and Code
Oct 21, 2019

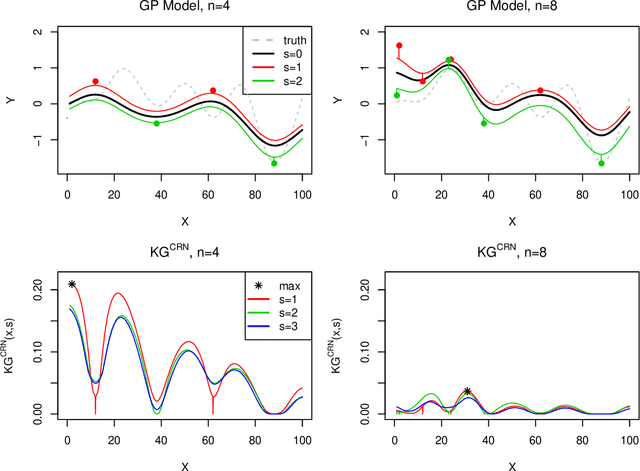
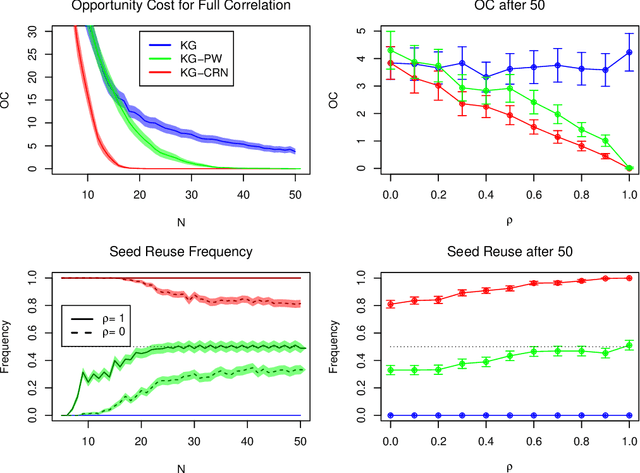
Bayesian optimization is a powerful tool for expensive stochastic black-box optimization problems such as simulation-based optimization or machine learning hyperparameter tuning. Many stochastic objective functions implicitly require a random number seed as input. By explicitly reusing a seed a user can exploit common random numbers, comparing two or more inputs under the same randomly generated scenario, such as a common customer stream in a job shop problem, or the same random partition of training data into training and validation set for a machine learning algorithm. With the aim of finding an input with the best average performance over infinitely many seeds, we propose a novel Gaussian process model that jointly models both the output for each seed and the average. We then introduce the Knowledge gradient for Common Random Numbers that iteratively determines a combination of input and random seed to evaluate the objective and automatically trades off reusing old seeds and querying new seeds, thus overcoming the need to evaluate inputs in batches or measuring differences of pairs as suggested in previous methods. We investigate the Knowledge Gradient for Common Random Numbers both theoretically and empirically, finding it achieves significant performance improvements with only moderate added computational cost.