Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Extensions of Kernel Least Mean Squares
Paper and Code
Oct 20, 2013
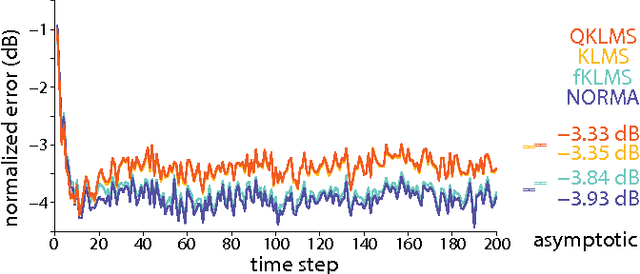
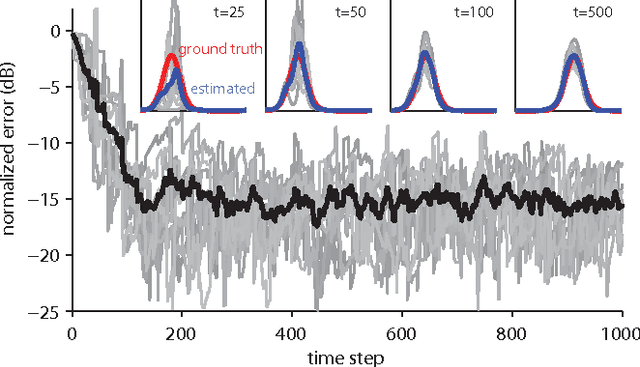

The kernel least mean squares (KLMS) algorithm is a computationally efficient nonlinear adaptive filtering method that "kernelizes" the celebrated (linear) least mean squares algorithm. We demonstrate that the least mean squares algorithm is closely related to the Kalman filtering, and thus, the KLMS can be interpreted as an approximate Bayesian filtering method. This allows us to systematically develop extensions of the KLMS by modifying the underlying state-space and observation models. The resulting extensions introduce many desirable properties such as "forgetting", and the ability to learn from discrete data, while retaining the computational simplicity and time complexity of the original algorithm.
* 7 pages, 4 fiures
View paper on