 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesCard: Revitilizing Bayesian Frameworks for Cardinality Estimation
Paper and Code
Feb 02, 2021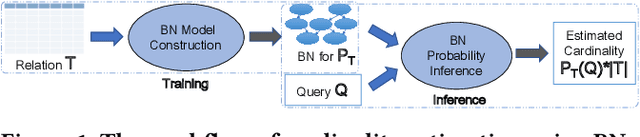
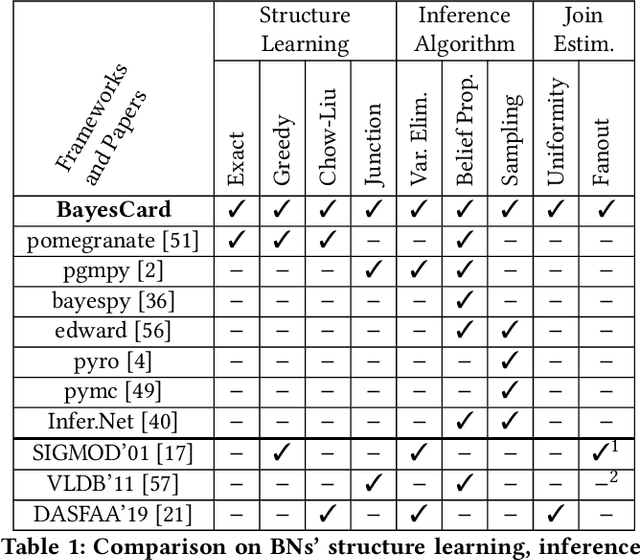
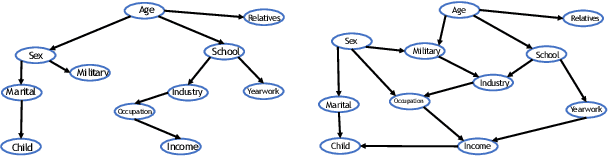

Cardinality estimation (CardEst) is an essential component in query optimizers and a fundamental problem in DBMS. A desired CardEst method should attain good algorithm performance, be stable to varied data settings, and be friendly to system deployment. However, no existing CardEst method can fulfill the three criteria at the same time. Traditional methods often have significant algorithm drawbacks such as large estimation errors. Recently proposed deep learning based methods largely improve the estimation accuracy but their performance can be greatly affected by data and often difficult for system deployment. In this paper, we revitalize the Bayesian networks (BN) for CardEst by incorporating the techniques of probabilistic programming languages. We present BayesCard, the first framework that inherits the advantages of BNs, i.e., high estimation accuracy and interpretability, while overcomes their drawbacks, i.e. low structure learning and inference efficiency. This makes BayesCard a perfect candidate for commercial DBMS deployment. Our experimental results on several single-table and multi-table benchmarks indicate BayesCard's superiority over existing state-of-the-art CardEst methods: BayesCard achieves comparable or better accuracy, 1-2 orders of magnitude faster inference time, 1-3 orders faster training time, 1-3 orders smaller model size, and 1-2 orders faster updates. Meanwhile, BayesCard keeps stable performance when varying data with different settings. We also deploy BayesCard into PostgreSQL. On the IMDB benchmark workload, it improves the end-to-end query time by 13.3%, which is very close to the optimal result of 14.2% using an oracle of true cardinality.