 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatchFormerV2: Exploring Sample Relationships for Dense Representation Learning
Paper and Code
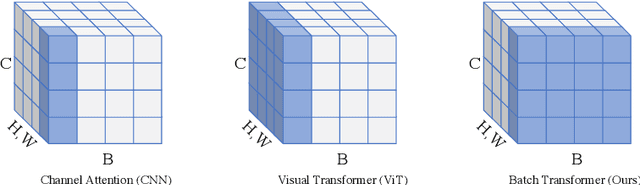

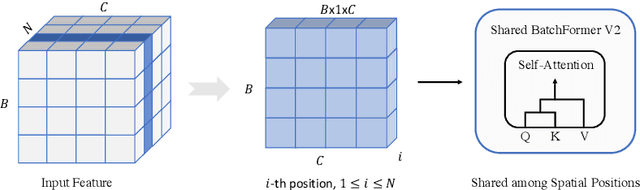

Attention mechanisms have been very popular in deep neural networks, where the Transformer architecture has achieved great success in not only natural language processing but also visual recognition applications. Recently, a new Transformer module, applying on batch dimension rather than spatial/channel dimension, i.e., BatchFormer [18], has been introduced to explore sample relationships for overcoming data scarcity challenges. However, it only works with image-level representations for classification. In this paper, we devise a more general batch Transformer module, BatchFormerV2, which further enables exploring sample relationships for dense representation learning. Specifically, when applying the proposed module, it employs a two-stream pipeline during training, i.e., either with or without a BatchFormerV2 module, where the batchformer stream can be removed for testing. Therefore, the proposed method is a plug-and-play module and can be easily integrated into different vision Transformers without any extra inference cost. Without bells and whistles, we show the effectiveness of the proposed method for a variety of popular visual recognition tasks, including image classification and two important dense prediction tasks: object detection and panoptic segmentation. Particularly, BatchFormerV2 consistently improves current DETR-based detection methods (e.g., DETR, Deformable-DETR, Conditional DETR, and SMCA) by over 1.3%. Code will be made publicly available.