 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAM: Bottleneck Attention Module
Paper and Code
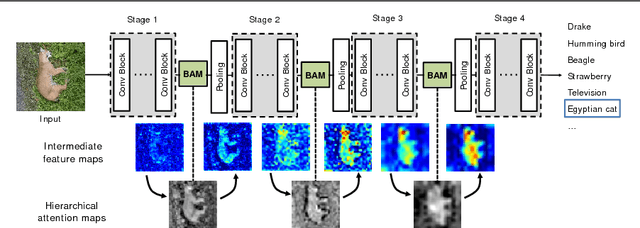


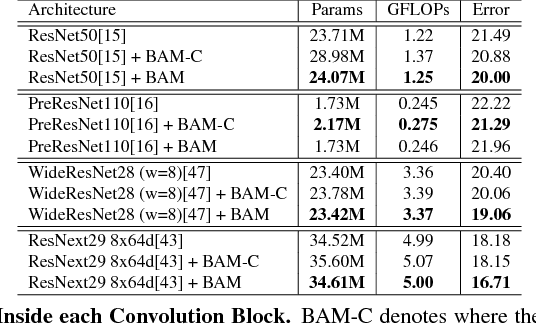
Recent advances in deep neural networks have been developed via architecture search for stronger representational power. In this work, we focus on the effect of attention in general deep neural networks. We propose a simple and effective attention module, named Bottleneck Attention Module (BAM), that can be integrated with any feed-forward convolutional neural networks. Our module infers an attention map along two separate pathways, channel and spatial. We place our module at each bottleneck of models where the downsampling of feature maps occurs. Our module constructs a hierarchical attention at bottlenecks with a number of parameters and it is trainable in an end-to-end manner jointly with any feed-forward models. We validate our BAM through extensive experiments on CIFAR-100, ImageNet-1K, VOC 2007 and MS COCO benchmarks. Our experiments show consistent improvement in classification and detection performances with various models, demonstrating the wide applicability of BAM. The code and models will be publicly available.