Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanceKV: KV Cache Compression through Discrepancy Theory
Paper and Code
Feb 11, 2025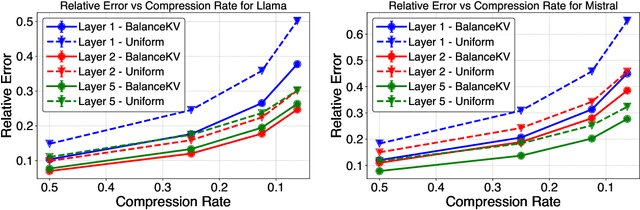

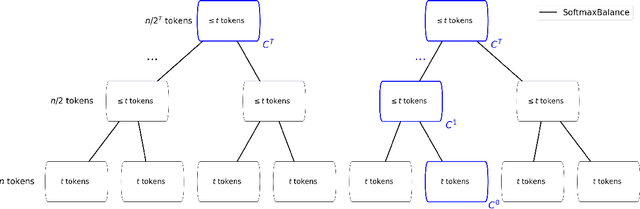

Large language models (LLMs) have achieved impressive success, but their high memory requirements present challenges for long-context token generation. The memory complexity of long-context LLMs is primarily due to the need to store Key-Value (KV) embeddings in their KV cache. We present BalanceKV, a KV cache compression method based on geometric sampling process stemming from Banaszczyk's vector balancing theory, which introduces dependencies informed by the geometry of keys and value tokens, and improves precision. BalanceKV offers both theoretically proven and empirically validated performance improvements over existing methods.
View paper on