Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Identifying Language Family from Acoustic Examples in Low Resource Scenarios
Paper and Code

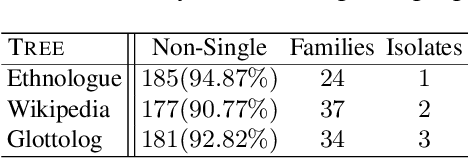


Existing multilingual speech NLP works focus on a relatively small subset of languages, and thus current linguistic understanding of languages predominantly stems from classical approaches. In this work, we propose a method to analyze language similarity using deep learning. Namely, we train a model on the Wilderness dataset and investigate how its latent space compares with classical language family findings. Our approach provides a new direction for cross-lingual data augmentation in any speech-based NLP task.
View paper on