 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoencoding Low-Resolution MRI for Semantically Smooth Interpolation of Anisotropic MRI
Paper and Code
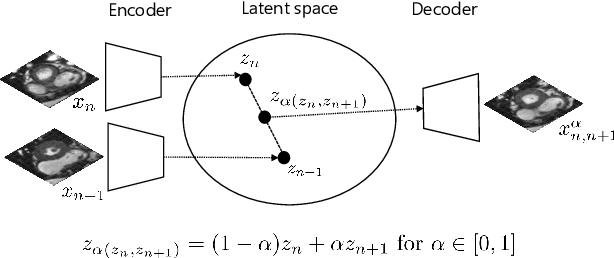
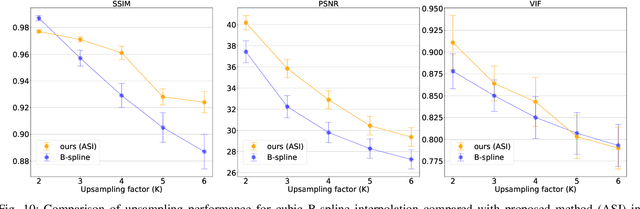

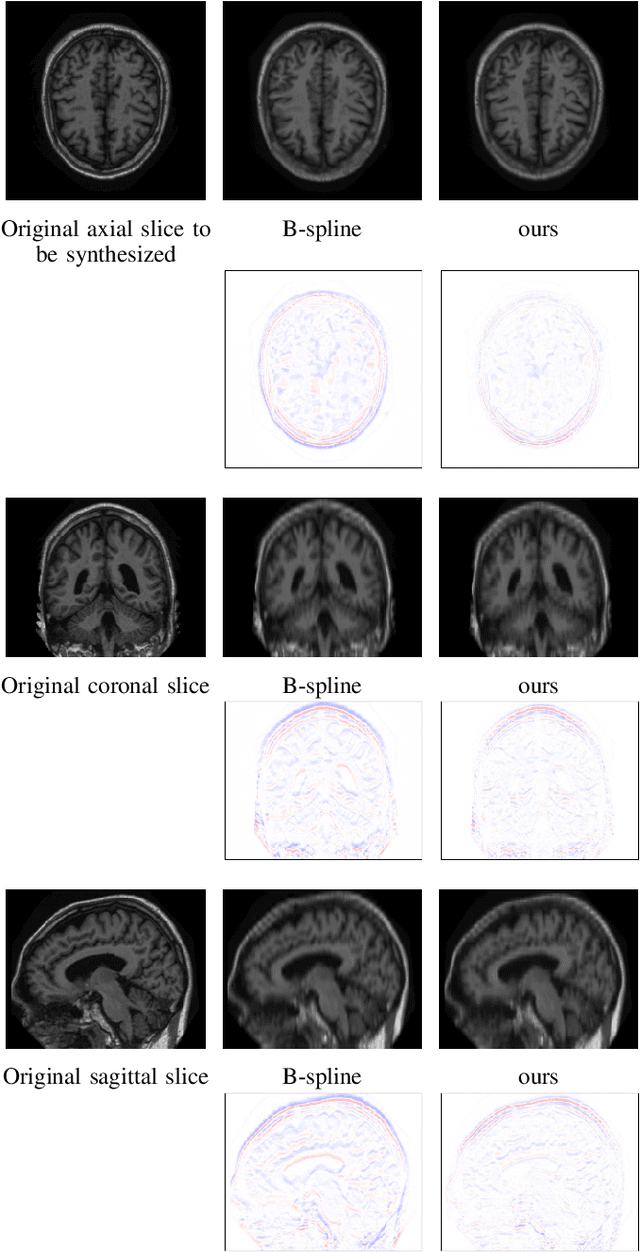
High-resolution medical images are beneficial for analysis but their acquisition may not always be feasible. Alternatively, high-resolution images can be created from low-resolution acquisitions using conventional upsampling methods, but such methods cannot exploit high-level contextual information contained in the images. Recently, better performing deep-learning based super-resolution methods have been introduced. However, these methods are limited by their supervised character, i.e. they require high-resolution examples for training. Instead, we propose an unsupervised deep learning semantic interpolation approach that synthesizes new intermediate slices from encoded low-resolution examples. To achieve semantically smooth interpolation in through-plane direction, the method exploits the latent space generated by autoencoders. To generate new intermediate slices, latent space encodings of two spatially adjacent slices are combined using their convex combination. Subsequently, the combined encoding is decoded to an intermediate slice. To constrain the model, a notion of semantic similarity is defined for a given dataset. For this, a new loss is introduced that exploits the spatial relationship between slices of the same volume. During training, an existing in-between slice is generated using a convex combination of its neighboring slice encodings. The method was trained and evaluated using publicly available cardiac cine, neonatal brain and adult brain MRI scans. In all evaluations, the new method produces significantly better results in terms of Structural Similarity Index Measure and Peak Signal-to-Noise Ratio (p< 0.001 using one-sided Wilcoxon signed-rank test) than a cubic B-spline interpolation approach. Given the unsupervised nature of the method, high-resolution training data is not required and hence, the method can be readily applied in clinical settings.