 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Vision Language Pretraining by Learning Codebook with Visual Semantics
Paper and Code
Jul 31, 2022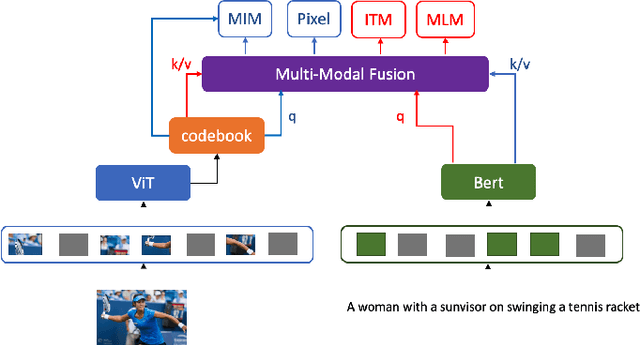



Language modality within the vision language pretraining framework is innately discretized, endowing each word in the language vocabulary a semantic meaning. In contrast, visual modality is inherently continuous and high-dimensional, which potentially prohibits the alignment as well as fusion between vision and language modalities. We therefore propose to "discretize" the visual representation by joint learning a codebook that imbues each visual token a semantic. We then utilize these discretized visual semantics as self-supervised ground-truths for building our Masked Image Modeling objective, a counterpart of Masked Language Modeling which proves successful for language models. To optimize the codebook, we extend the formulation of VQ-VAE which gives a theoretic guarantee. Experiments validate the effectiveness of our approach across common vision-language benchmarks.