Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing ML Models for Individual Bias and Unfairness
Paper and Code
Mar 11, 2020

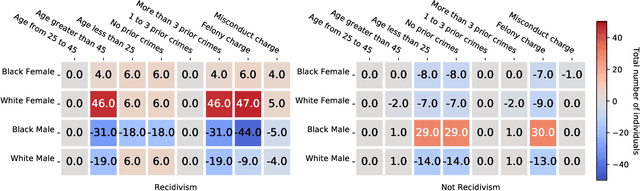
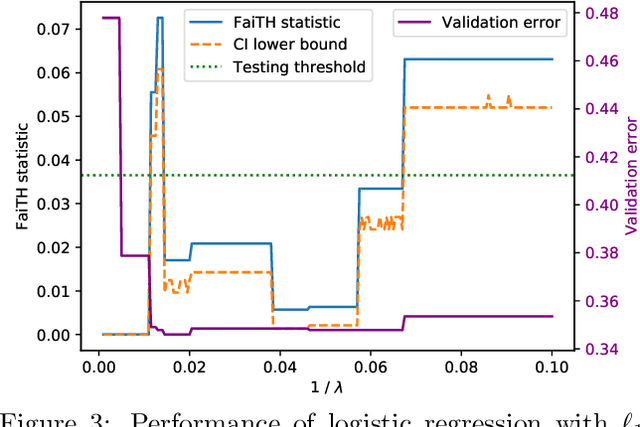
We consider the task of auditing ML models for individual bias/unfairness. We formalize the task in an optimization problem and develop a suite of inferential tools for the optimal value. Our tools permit us to obtain asymptotic confidence intervals and hypothesis tests that cover the target/control the Type I error rate exactly. To demonstrate the utility of our tools, we use them to reveal the gender and racial biases in Northpointe's COMPAS recidivism prediction instrument.
* In Proceedings of the 23rd International Conference on Artificial
Intelligence and Statistics (AISTATS) 2020
View paper on