 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Captioning using Pre-Trained Large-Scale Language Model Guided by Audio-based Similar Caption Retrieval
Paper and Code
Dec 14, 2020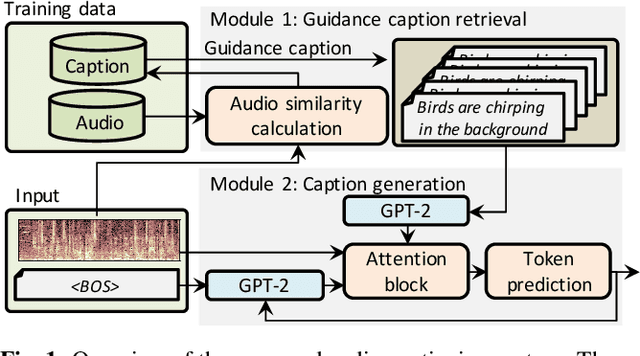
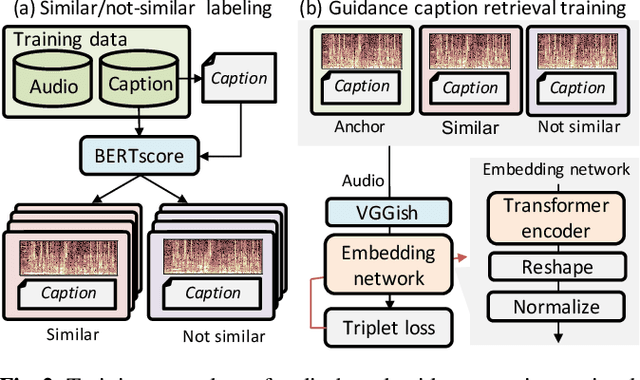
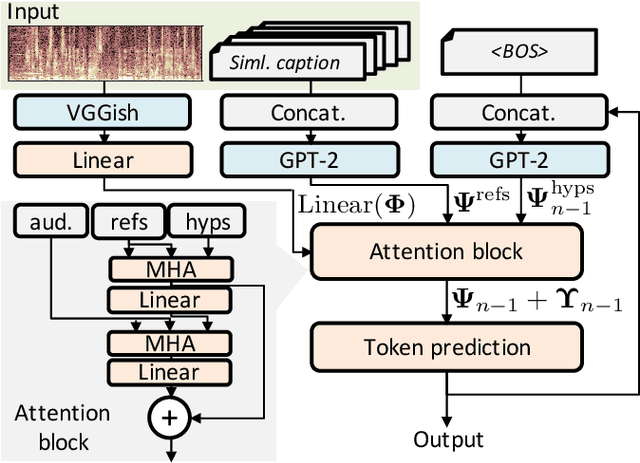
The goal of audio captioning is to translate input audio into its description using natural language. One of the problems in audio captioning is the lack of training data due to the difficulty in collecting audio-caption pairs by crawling the web. In this study, to overcome this problem, we propose to use a pre-trained large-scale language model. Since an audio input cannot be directly inputted into such a language model, we utilize guidance captions retrieved from a training dataset based on similarities that may exist in different audio. Then, the caption of the audio input is generated by using a pre-trained language model while referring to the guidance captions. Experimental results show that (i) the proposed method has succeeded to use a pre-trained language model for audio captioning, and (ii) the oracle performance of the pre-trained model-based caption generator was clearly better than that of the conventional method trained from scratch.