 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Descent: Simulating Object-Centric Datasets on the Content Level and Beyond
Paper and Code
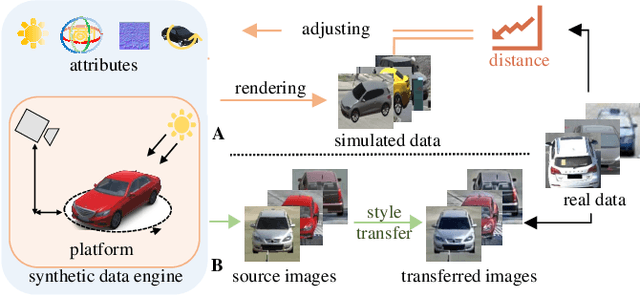



This article aims to use graphic engines to simulate a large number of training data that have free annotations and possibly strongly resemble to real-world data. Between synthetic and real, a two-level domain gap exists, involving content level and appearance level. While the latter is concerned with appearance style, the former problem arises from a different mechanism, i.e., content mismatch in attributes such as camera viewpoint, object placement and lighting conditions. In contrast to the widely-studied appearance-level gap, the content-level discrepancy has not been broadly studied. To address the content-level misalignment, we propose an attribute descent approach that automatically optimizes engine attributes to enable synthetic data to approximate real-world data. We verify our method on object-centric tasks, wherein an object takes up a major portion of an image. In these tasks, the search space is relatively small, and the optimization of each attribute yields sufficiently obvious supervision signals. We collect a new synthetic asset VehicleX, and reformat and reuse existing the synthetic assets ObjectX and PersonX. Extensive experiments on image classification and object re-identification confirm that adapted synthetic data can be effectively used in three scenarios: training with synthetic data only, training data augmentation and numerically understanding dataset content.