 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentional Network for Visual Object Detection
Paper and Code
Feb 06, 2017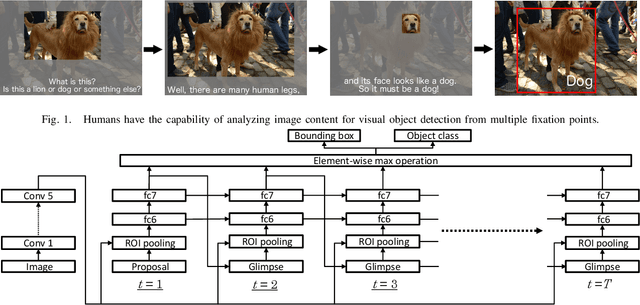


We propose augmenting deep neural networks with an attention mechanism for the visual object detection task. As perceiving a scene, humans have the capability of multiple fixation points, each attended to scene content at different locations and scales. However, such a mechanism is missing in the current state-of-the-art visual object detection methods. Inspired by the human vision system, we propose a novel deep network architecture that imitates this attention mechanism. As detecting objects in an image, the network adaptively places a sequence of glimpses of different shapes at different locations in the image. Evidences of the presence of an object and its location are extracted from these glimpses, which are then fused for estimating the object class and bounding box coordinates. Due to lacks of ground truth annotations of the visual attention mechanism, we train our network using a reinforcement learning algorithm with policy gradients. Experiment results on standard object detection benchmarks show that the proposed network consistently outperforms the baseline networks that does not model the attention mechanism.