 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentional Mixtures of Soft Prompt Tuning for Parameter-efficient Multi-task Knowledge Sharing
Paper and Code
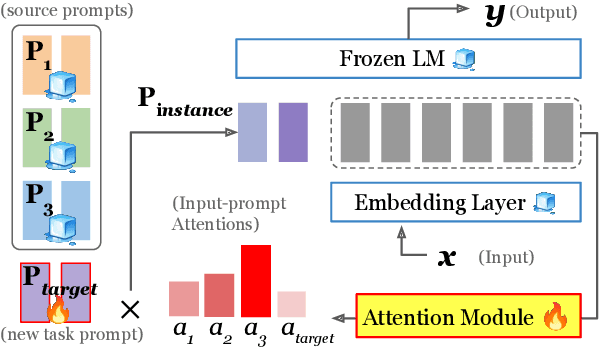

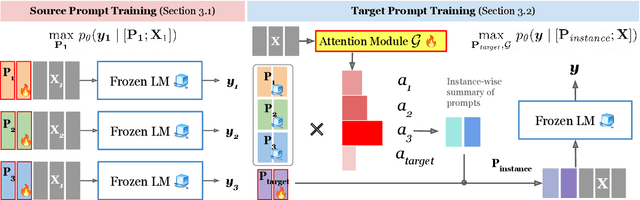
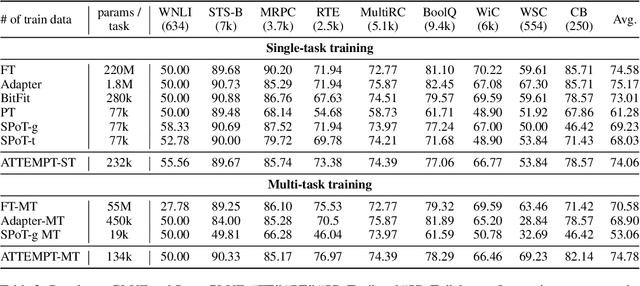
This work introduces ATTEMPT (Attentional Mixture of Prompt Tuning), a new modular, multi-task, and parameter-efficient language model (LM) tuning approach that combines knowledge transferred across different tasks via a mixture of soft prompts while keeping original LM unchanged. ATTEMPT interpolates a set of prompts trained on large-scale source tasks and a newly initialized target task prompt using instance-wise attention computed by a lightweight sub-network trained on multiple target tasks. ATTEMPT is parameter-efficient (e.g., updates 1,600 times fewer parameters than fine-tuning) and enables multi-task learning and flexible extensions; importantly, it is also more interpretable because it demonstrates which source tasks affect the final model decision on target tasks. Experimental results across 17 diverse datasets show that ATTEMPT improves prompt tuning by up to a 22% absolute performance gain and outperforms or matches fully fine-tuned or other parameter-efficient tuning approaches that use over ten times more parameters.