 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Multi-hypothesis Fusion for Speech Summarization
Paper and Code
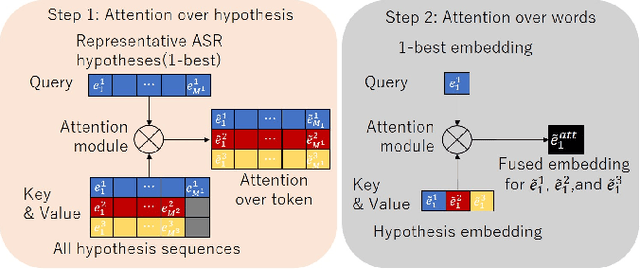

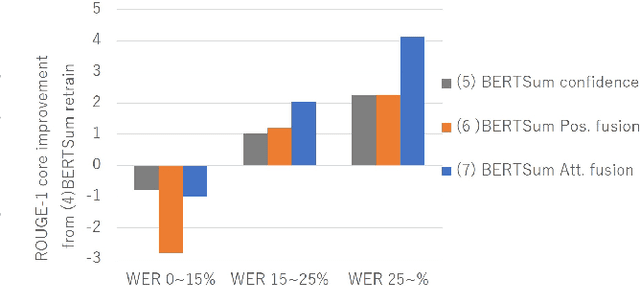

Speech summarization, which generates a text summary from speech, can be achieved by combining automatic speech recognition (ASR) and text summarization (TS). With this cascade approach, we can exploit state-of-the-art models and large training datasets for both subtasks, i.e., Transformer for ASR and Bidirectional Encoder Representations from Transformers (BERT) for TS. However, ASR errors directly affect the quality of the output summary in the cascade approach. We propose a cascade speech summarization model that is robust to ASR errors and that exploits multiple hypotheses generated by ASR to attenuate the effect of ASR errors on the summary. We investigate several schemes to combine ASR hypotheses. First, we propose using the sum of sub-word embedding vectors weighted by their posterior values provided by an ASR system as an input to a BERT-based TS system. Then, we introduce a more general scheme that uses an attention-based fusion module added to a pre-trained BERT module to align and combine several ASR hypotheses. Finally, we perform speech summarization experiments on the How2 dataset and a newly assembled TED-based dataset that we will release with this paper. These experiments show that retraining the BERT-based TS system with these schemes can improve summarization performance and that the attention-based fusion module is particularly effective.