 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Policy Evaluation in Distributed Reinforcement Learning over Networks
Paper and Code
Mar 01, 2020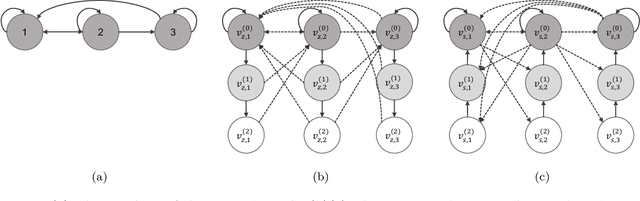
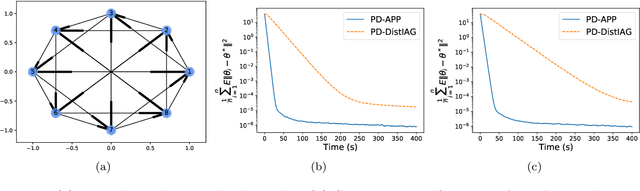
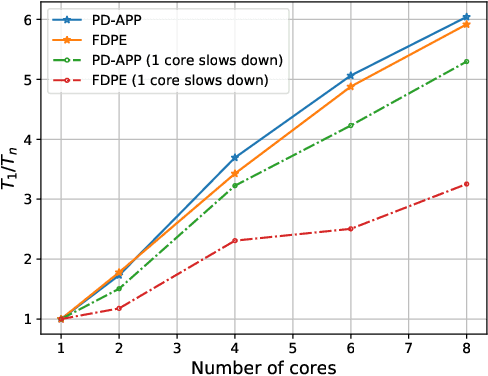
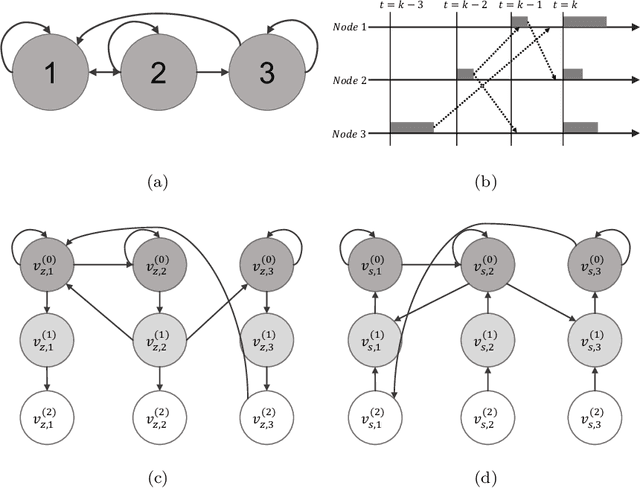
This paper proposes a \emph{fully asynchronous} scheme for policy evaluation of distributed reinforcement learning (DisRL) over peer-to-peer networks. Without any form of coordination, nodes can communicate with neighbors and compute their local variables using (possibly) delayed information at any time, which is in sharp contrast to the asynchronous gossip. Thus, the proposed scheme fully takes advantage of the distributed setting. We prove that our method converges at a linear rate $\mathcal{O}(c^k)$ where $c\in(0,1)$ and $k$ increases by one no matter on which node updates, showing the computational advantage by reducing the amount of synchronization. Numerical experiments show that our method speeds up linearly w.r.t. the number of nodes, and is robust to straggler nodes. To the best of our knowledge, our work is the first theoretical analysis for asynchronous update in DisRL, including the \emph{parallel RL} domain advocated by A3C.