 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotic learning curves of kernel methods: empirical data v.s. Teacher-Student paradigm
Paper and Code
Jun 06, 2019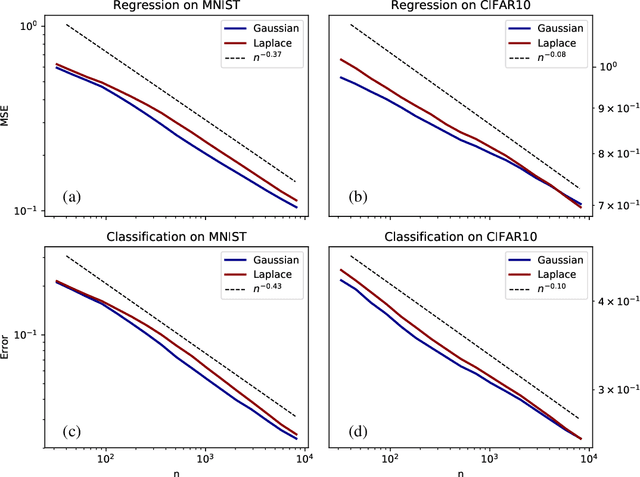
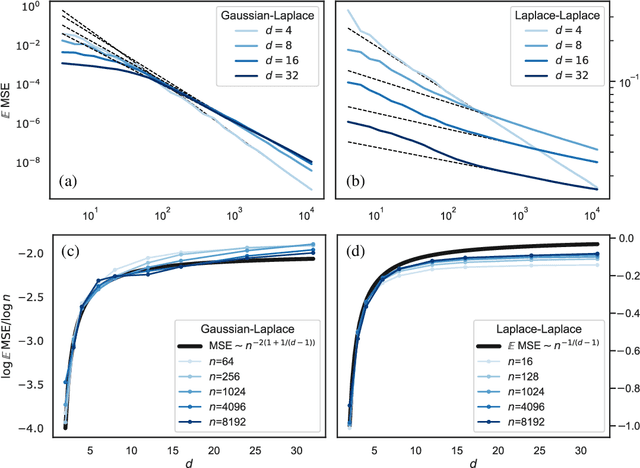
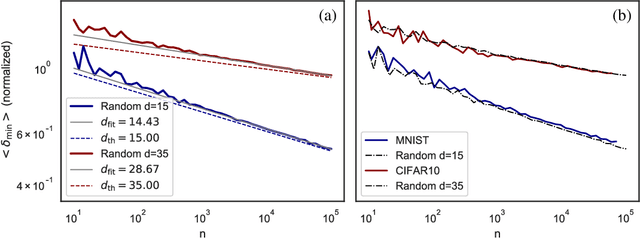
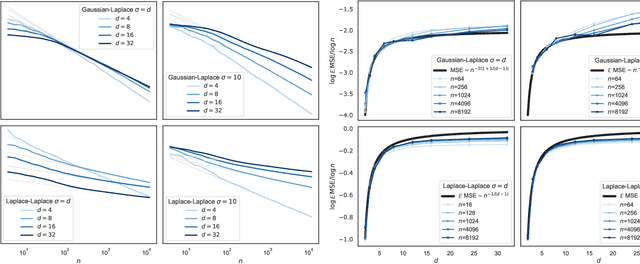
How many training data are needed to learn a supervised task? It is often observed that the generalization error decreases as $n^{-\beta}$ where $n$ is the number of training examples and $\beta$ an exponent that depends on both data and algorithm. In this work we measure $\beta$ when applying kernel methods to real datasets. For MNIST we find $\beta\approx 0.4$ and for CIFAR10 $\beta\approx 0.1$. Remarkably, $\beta$ is the same for regression and classification tasks, and for Gaussian or Laplace kernels. To rationalize the existence of non-trivial exponents that can be independent of the specific kernel used, we introduce the Teacher-Student framework for kernels. In this scheme, a Teacher generates data according to a Gaussian random field, and a Student learns them via kernel regression. With a simplifying assumption --- namely that the data are sampled from a regular lattice --- we derive analytically $\beta$ for translation invariant kernels, using previous results from the kriging literature. Provided that the Student is not too sensitive to high frequencies, $\beta$ depends only on the training data and their dimension. We confirm numerically that these predictions hold when the training points are sampled at random on a hypersphere. Overall, our results quantify how smooth Gaussian data should be to avoid the curse of dimensionality, and indicate that for kernel learning the relevant dimension of the data should be defined in terms of how the distance between nearest data points depends on $n$. With this definition one obtains reasonable effective smoothness estimates for MNIST and CIFAR10.