 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotic Behavior of Adversarial Training in Binary Classification
Paper and Code
Oct 26, 2020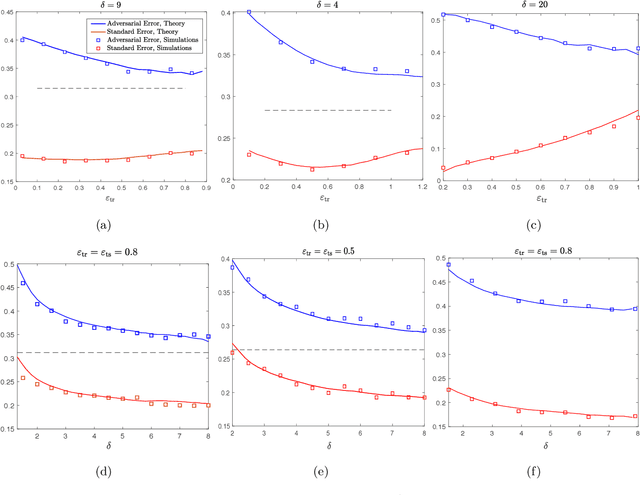

It is widely known that several machine learning models are susceptible to adversarial attacks i.e., small adversarial perturbations applied to data points causing the model to misclassify the data. Adversarial training using empirical risk minimization methods, is the state-of-the-art method for defense against adversarial attacks. Despite being successful, several problems in understanding generalization performance of adversarial training remain open. In this paper, we derive precise theoretical predictions for the performance of adversarial training in binary linear classification. We consider the modern high-dimensional regime where the dimension of data grows with the size of the training dataset at a constant ratio. Our results provide exact asymptotics for the performance of estimators obtained by adversarial training with $\ell_q$-norm bounded perturbations ($q \ge 1$) and for binary labels and Gaussian features. These sharp predictions enable us to explore the role of various factors including over-parametrization ratio, data model and attack budget on the performance of adversarial training.