 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssociative Memories to Accelerate Approximate Nearest Neighbor Search
Paper and Code
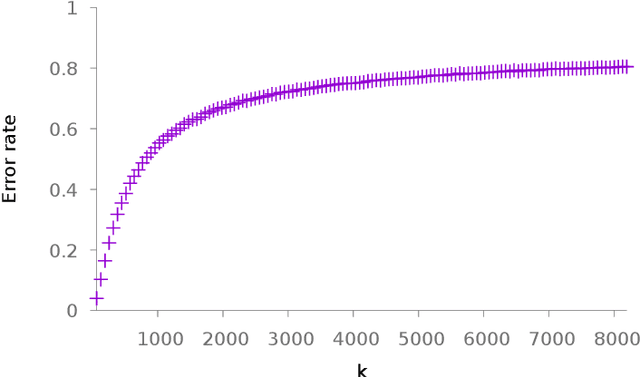

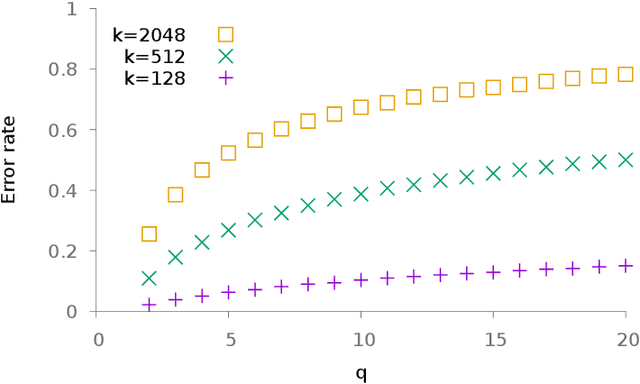

Nearest neighbor search is a very active field in machine learning for it appears in many application cases, including classification and object retrieval. In its canonical version, the complexity of the search is linear with both the dimension and the cardinal of the collection of vectors the search is performed in. Recently many works have focused on reducing the dimension of vectors using quantization techniques or hashing, while providing an approximate result. In this paper we focus instead on tackling the cardinal of the collection of vectors. Namely, we introduce a technique that partitions the collection of vectors and stores each part in its own associative memory. When a query vector is given to the system, associative memories are polled to identify which one contain the closest match. Then an exhaustive search is conducted only on the part of vectors stored in the selected associative memory. We study the effectiveness of the system when messages to store are generated from i.i.d. uniform $\pm$1 random variables or 0-1 sparse i.i.d. random variables. We also conduct experiment on both synthetic data and real data and show it is possible to achieve interesting trade-offs between complexity and accuracy.