 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Reliability of Large Language Model Knowledge
Paper and Code
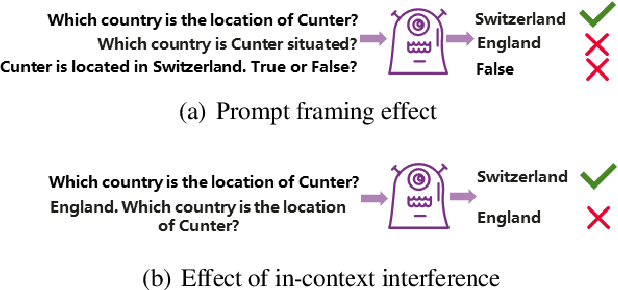

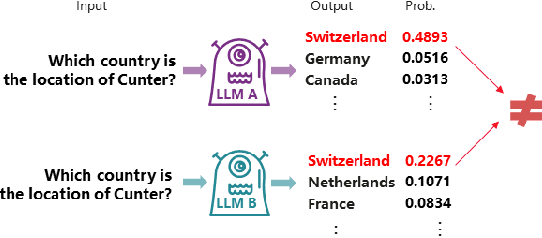
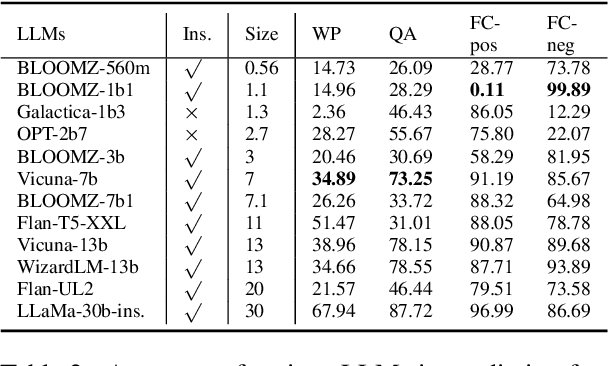
Large language models (LLMs) have been treated as knowledge bases due to their strong performance in knowledge probing tasks. LLMs are typically evaluated using accuracy, yet this metric does not capture the vulnerability of LLMs to hallucination-inducing factors like prompt and context variability. How do we evaluate the capabilities of LLMs to consistently produce factually correct answers? In this paper, we propose MOdel kNowledge relIabiliTy scORe (MONITOR), a novel metric designed to directly measure LLMs' factual reliability. MONITOR computes the distance between the probability distributions of a valid output and its counterparts produced by the same LLM probing the same fact using different styles of prompts and contexts.Experiments on a comprehensive range of 12 LLMs demonstrate the effectiveness of MONITOR in evaluating the factual reliability of LLMs while maintaining a low computational overhead. In addition, we release the FKTC (Factual Knowledge Test Corpus) test set, containing 210,158 prompts in total to foster research along this line (https://github.com/Vicky-Wil/MONITOR).