 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Quality of Scientific Papers
Paper and Code
Aug 12, 2019


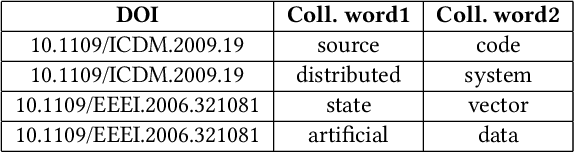
A multitude of factors are responsible for the overall quality of scientific papers, including readability, linguistic quality, fluency,semantic complexity, and of course domain-specific technical factors. These factors vary from one field of study to another. In this paper, we propose a measure and method for assessing the overall quality of the scientific papers in a particular field of study. We evaluate our method in the computer science domain, but it can be applied to other technical and scientific fields.Our method is based on the corpus linguistics technique. This technique enables the extraction of required information and knowledge associated with a specific domain. For this purpose, we have created a large corpus, consisting of papers from very high impact conferences. First, we analyze this corpus in order to extract rich domain-specific terminology and knowledge. Then we use the acquired knowledge to estimate the quality of scientific papers by applying our proposed measure. We examine our measure on high and low scientific impact test corpora. Our results show a significant difference in the measure scores of the high and low impact test corpora. Second, we develop a classifier based on our proposed measure and compare it to the baseline classifier. Our results show that the classifier based on our measure over-performed the baseline classifier. Based on the presented results the proposed measure and the technique can be used for automated assessment of scientific papers.