 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Robustness of Text Classification through Maximal Safe Radius Computation
Paper and Code

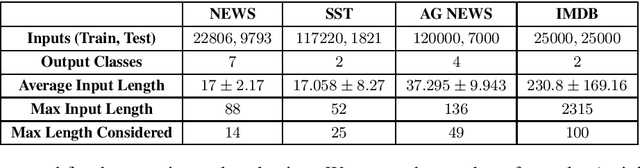

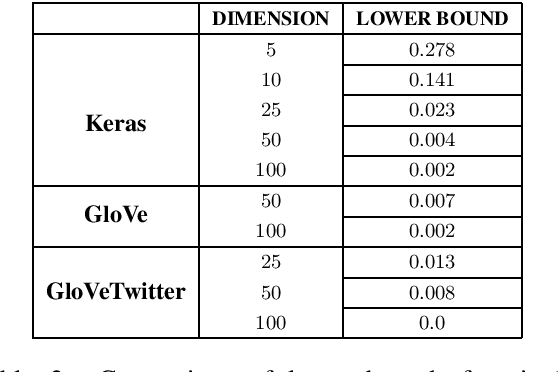
Neural network NLP models are vulnerable to small modifications of the input that maintain the original meaning but result in a different prediction. In this paper, we focus on robustness of text classification against word substitutions, aiming to provide guarantees that the model prediction does not change if a word is replaced with a plausible alternative, such as a synonym. As a measure of robustness, we adopt the notion of the maximal safe radius for a given input text, which is the minimum distance in the embedding space to the decision boundary. Since computing the exact maximal safe radius is not feasible in practice, we instead approximate it by computing a lower and upper bound. For the upper bound computation, we employ Monte Carlo Tree Search in conjunction with syntactic filtering to analyse the effect of single and multiple word substitutions. The lower bound computation is achieved through an adaptation of the linear bounding techniques implemented in tools CNN-Cert and POPQORN, respectively for convolutional and recurrent network models. We evaluate the methods on sentiment analysis and news classification models for four datasets (IMDB, SST, AG News and NEWS) and a range of embeddings, and provide an analysis of robustness trends. We also apply our framework to interpretability analysis and compare it with LIME.