 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAspect-Oriented Summarization through Query-Focused Extraction
Paper and Code


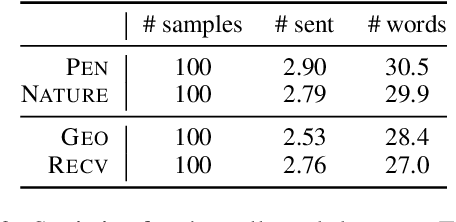

A reader interested in a particular topic might be interested in summarizing documents on that subject with a particular focus, rather than simply seeing generic summaries produced by most summarization systems. While query-focused summarization has been explored in prior work, this is often approached from the standpoint of document-specific questions or on synthetic data. Real users' needs often fall more closely into aspects, broad topics in a dataset the user is interested in rather than specific queries. In this paper, we collect a dataset of realistic aspect-oriented test cases, AspectNews, which covers different subtopics about articles in news sub-domains. We then investigate how query-focused methods, for which we can construct synthetic data, can handle this aspect-oriented setting: we benchmark extractive query-focused training schemes, and propose a contrastive augmentation approach to train the model. We evaluate on two aspect-oriented datasets and find this approach yields (a) focused summaries, better than those from a generic summarization system, which go beyond simple keyword matching; (b) a system sensitive to the choice of keywords.