 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASKIT: Approximate Skeletonization Kernel-Independent Treecode in High Dimensions
Paper and Code
Mar 13, 2015
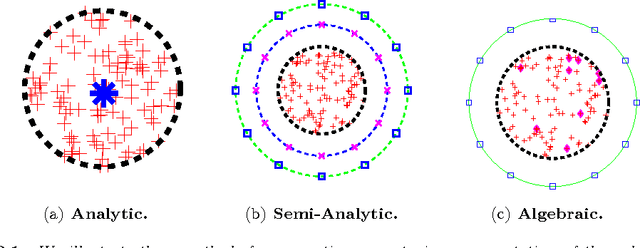
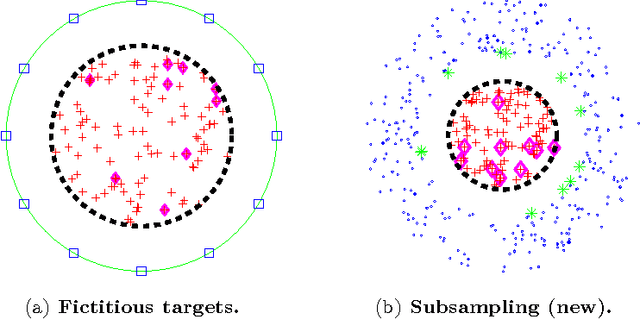
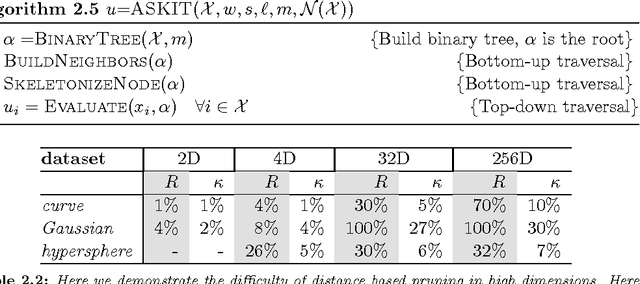
We present a fast algorithm for kernel summation problems in high-dimensions. These problems appear in computational physics, numerical approximation, non-parametric statistics, and machine learning. In our context, the sums depend on a kernel function that is a pair potential defined on a dataset of points in a high-dimensional Euclidean space. A direct evaluation of the sum scales quadratically with the number of points. Fast kernel summation methods can reduce this cost to linear complexity, but the constants involved do not scale well with the dimensionality of the dataset. The main algorithmic components of fast kernel summation algorithms are the separation of the kernel sum between near and far field (which is the basis for pruning) and the efficient and accurate approximation of the far field. We introduce novel methods for pruning and approximating the far field. Our far field approximation requires only kernel evaluations and does not use analytic expansions. Pruning is not done using bounding boxes but rather combinatorially using a sparsified nearest-neighbor graph of the input. The time complexity of our algorithm depends linearly on the ambient dimension. The error in the algorithm depends on the low-rank approximability of the far field, which in turn depends on the kernel function and on the intrinsic dimensionality of the distribution of the points. The error of the far field approximation does not depend on the ambient dimension. We present the new algorithm along with experimental results that demonstrate its performance. We report results for Gaussian kernel sums for 100 million points in 64 dimensions, for one million points in 1000 dimensions, and for problems in which the Gaussian kernel has a variable bandwidth. To the best of our knowledge, all of these experiments are impossible or prohibitively expensive with existing fast kernel summation methods.