 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASCNet: Action Semantic Consistent Learning of Arbitrary Progress Levels for Early Action Prediction
Paper and Code
Jan 23, 2022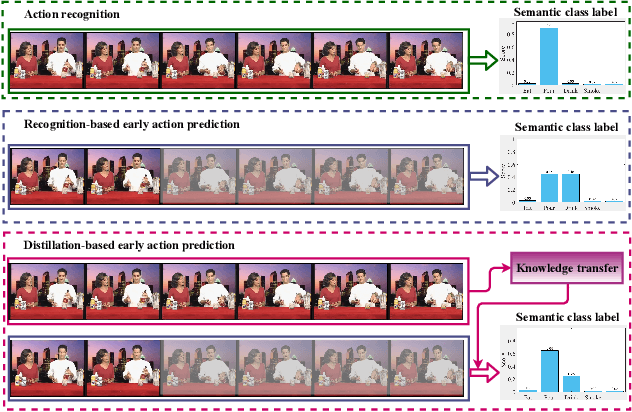
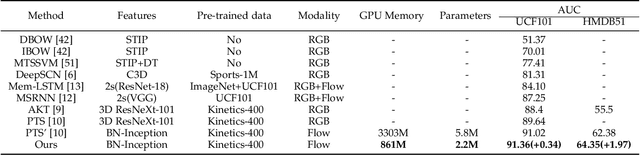
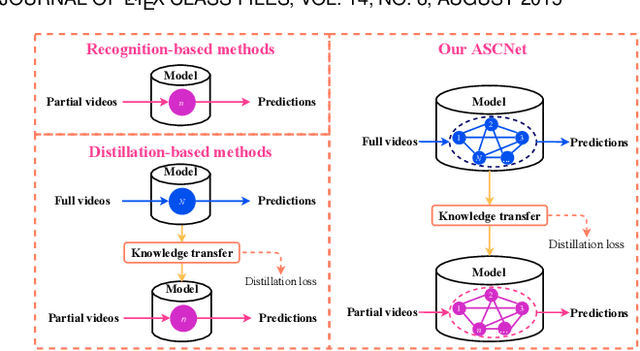
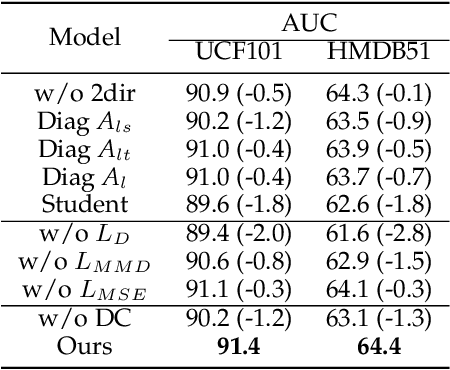
Early action prediction aims to recognize human actions from only a part of action execution, which is an important video analysis task for many practical applications. Most prior works treat partial or full videos as a whole, which neglects the semantic consistencies among partial videos of various progress levels due to their large intra-class variances. In contrast, we partition original partial or full videos to form a series of new partial videos and mine the Action Semantic Consistent Knowledge (ASCK) among these new partial videos evolving in arbitrary progress levels. Moreover, a novel Action Semantic Consistent learning network (ASCNet) under the teacher-student framework is proposed for early action prediction. Specifically, we treat partial videos as nodes and their action semantic consistencies as edges. Then we build a bi-directional fully connected graph for the teacher network and a single-directional fully connected graph for the student network to model ASCK among partial videos. The MSE and MMD losses are incorporated as our distillation loss to further transfer the ASCK from the teacher to the student network. Extensive experiments and ablative studies have been conducted, demonstrating the effectiveness of modeling ASCK for early action prediction. With the proposed ASCNet, we have achieved state-of-the-art performance on two benchmarks. The code will be released if the paper is accepted.