 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey Information Extraction From Documents: Evaluation And Generator
Paper and Code
Jun 09, 2021
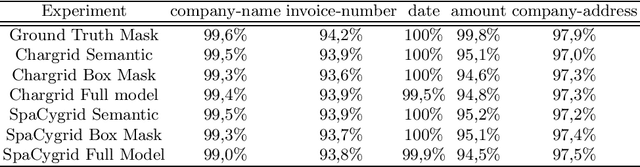
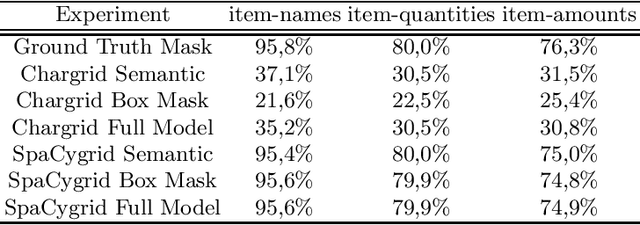
Extracting information from documents usually relies on natural language processing methods working on one-dimensional sequences of text. In some cases, for example, for the extraction of key information from semi-structured documents, such as invoice-documents, spatial and formatting information of text are crucial to understand the contextual meaning. Convolutional neural networks are already common in computer vision models to process and extract relationships in multidimensional data. Therefore, natural language processing models have already been combined with computer vision models in the past, to benefit from e.g. positional information and to improve performance of these key information extraction models. Existing models were either trained on unpublished data sets or on an annotated collection of receipts, which did not focus on PDF-like documents. Hence, in this research project a template-based document generator was created to compare state-of-the-art models for information extraction. An existing information extraction model "Chargrid" (Katti et al., 2019) was reconstructed and the impact of a bounding box regression decoder, as well as the impact of an NLP pre-processing step was evaluated for information extraction from documents. The results have shown that NLP based pre-processing is beneficial for model performance. However, the use of a bounding box regression decoder increases the model performance only for fields that do not follow a rectangular shape.