 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre You Tampering With My Data?
Paper and Code



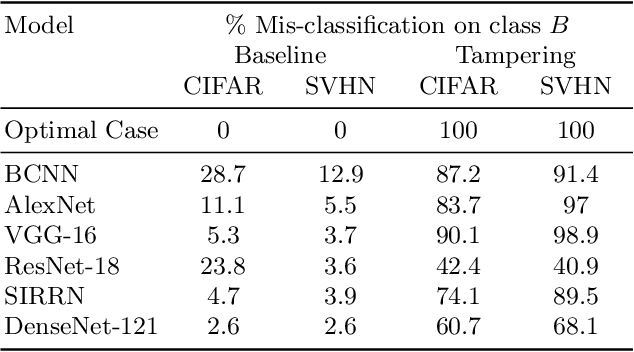
We propose a novel approach towards adversarial attacks on neural networks (NN), focusing on tampering the data used for training instead of generating attacks on trained models. Our network-agnostic method creates a backdoor during training which can be exploited at test time to force a neural network to exhibit abnormal behaviour. We demonstrate on two widely used datasets (CIFAR-10 and SVHN) that a universal modification of just one pixel per image for all the images of a class in the training set is enough to corrupt the training procedure of several state-of-the-art deep neural networks causing the networks to misclassify any images to which the modification is applied. Our aim is to bring to the attention of the machine learning community, the possibility that even learning-based methods that are personally trained on public datasets can be subject to attacks by a skillful adversary.