 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating probabilistic models as weighted finite automata
Paper and Code
May 21, 2019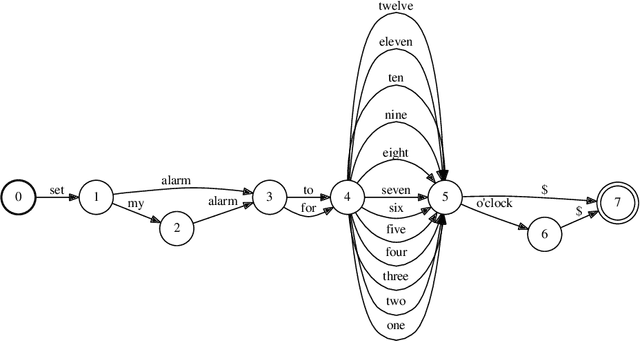

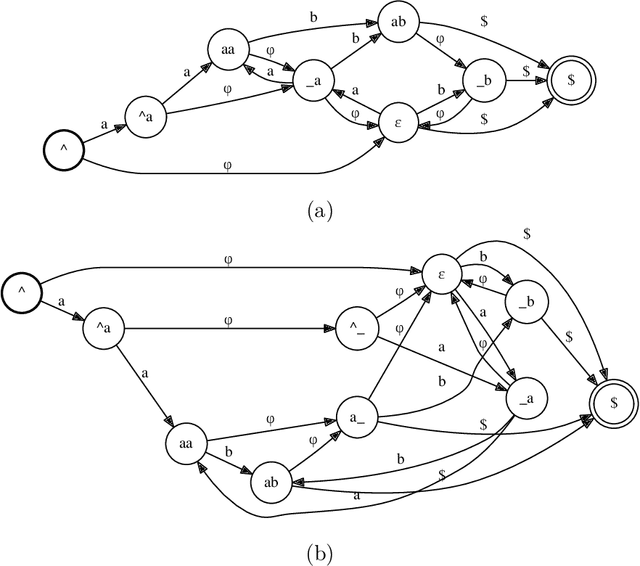

Weighted finite automata (WFA) are often used to represent probabilistic models, such as $n$-gram language models, since they are efficient for recognition tasks in time and space. The probabilistic source to be represented as a WFA, however, may come in many forms. Given a generic probabilistic model over sequences, we propose an algorithm to approximate it as a weighted finite automaton such that the Kullback-Leiber divergence between the source model and the WFA target model is minimized. The proposed algorithm involves a counting step and a difference of convex optimization, both of which can be performed efficiently. We demonstrate the usefulness of our approach on various tasks, including distilling $n$-gram models from neural models, building compact language models, and building open-vocabulary character models.