 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPE: Aligning Pretrained Encoders to Quickly Learn Aligned Multimodal Representations
Paper and Code
Oct 08, 2022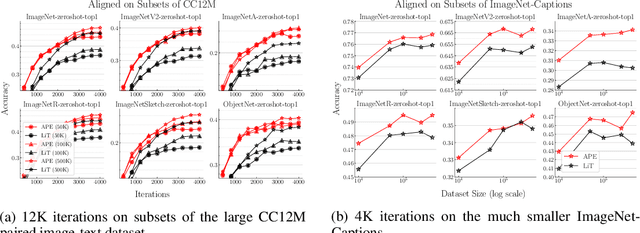
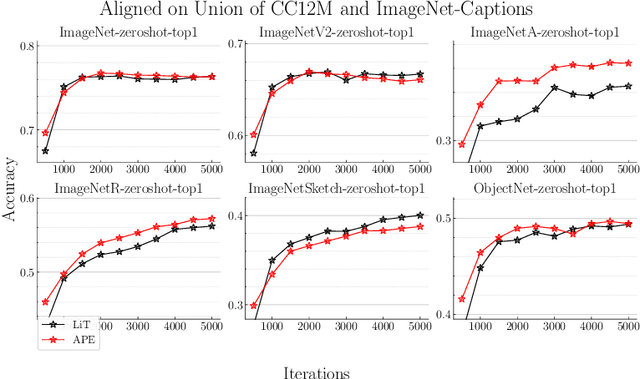
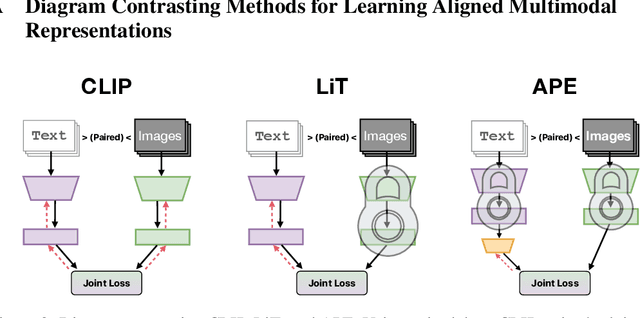
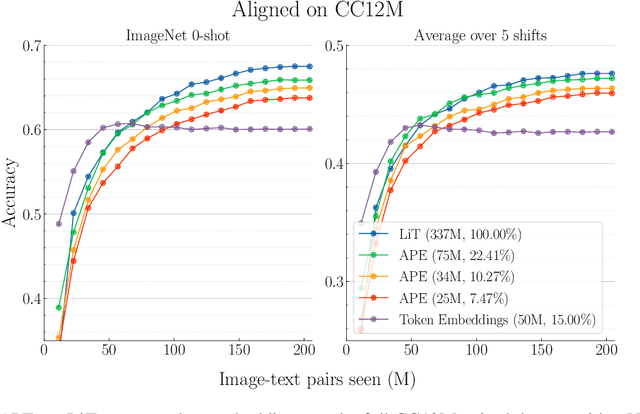
Recent advances in learning aligned multimodal representations have been primarily driven by training large neural networks on massive, noisy paired-modality datasets. In this work, we ask whether it is possible to achieve similar results with substantially less training time and data. We achieve this by taking advantage of existing pretrained unimodal encoders and careful curation of alignment data relevant to the downstream task of interest. We study a natural approach to aligning existing encoders via small auxiliary functions, and we find that this method is competitive with (or outperforms) state of the art in many settings while being less prone to overfitting, less costly to train, and more robust to distribution shift. With a properly chosen alignment distribution, our method surpasses prior state of the art for ImageNet zero-shot classification on public data while using two orders of magnitude less time and data and training 77% fewer parameters.