 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the tree-layer structure of Deep Forests
Paper and Code
Oct 29, 2020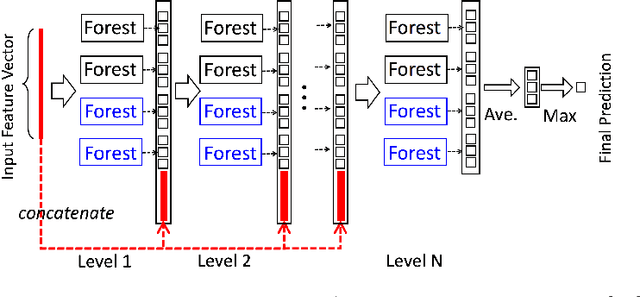
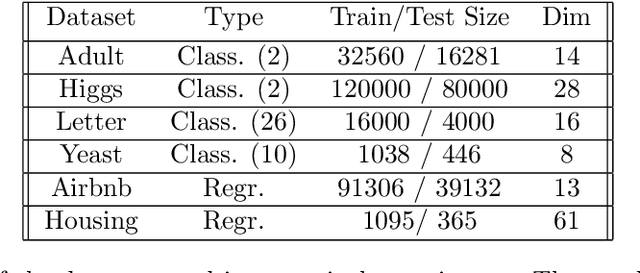
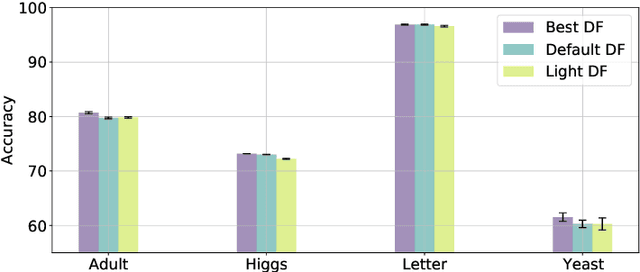
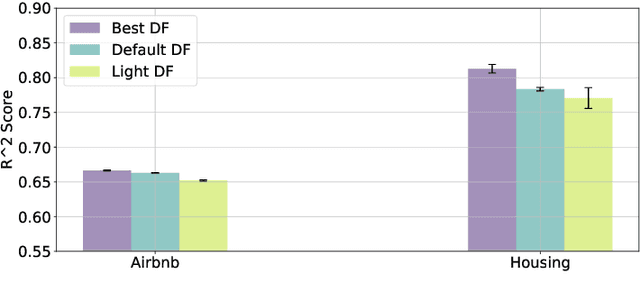
Random forests on the one hand, and neural networks on the other hand, have met great success in the machine learning community for their predictive performance. Combinations of both have been proposed in the literature, notably leading to the so-called deep forests (DF) [25]. In this paper, we investigate the mechanisms at work in DF and outline that DF architecture can generally be simplified into more simple and computationally efficient shallow forests networks. Despite some instability, the latter may outperform standard predictive tree-based methods. In order to precisely quantify the improvement achieved by these light network configurations over standard tree learners, we theoretically study the performance of a shallow tree network made of two layers, each one composed of a single centered tree. We provide tight theoretical lower and upper bounds on its excess risk. These theoretical results show the interest of tree-network architectures for well-structured data provided that the first layer, acting as a data encoder, is rich enough.