Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis on Gradient Propagation in Batch Normalized Residual Networks
Paper and Code
Dec 02, 2018


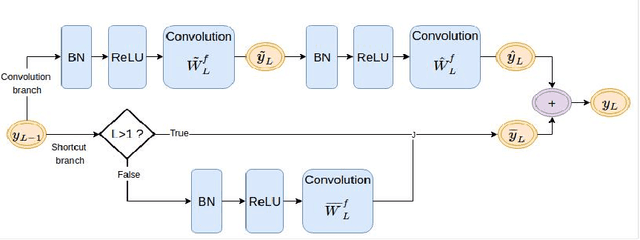
We conduct mathematical analysis on the effect of batch normalization (BN) on gradient backpropogation in residual network training, which is believed to play a critical role in addressing the gradient vanishing/explosion problem, in this work. By analyzing the mean and variance behavior of the input and the gradient in the forward and backward passes through the BN and residual branches, respectively, we show that they work together to confine the gradient variance to a certain range across residual blocks in backpropagation. As a result, the gradient vanishing/explosion problem is avoided. We also show the relative importance of batch normalization w.r.t. the residual branches in residual networks.
View paper on
 OpenReview
OpenReview