 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Hyper-Parameters for Small Games: Iterations or Epochs in Self-Play?
Paper and Code
Mar 12, 2020
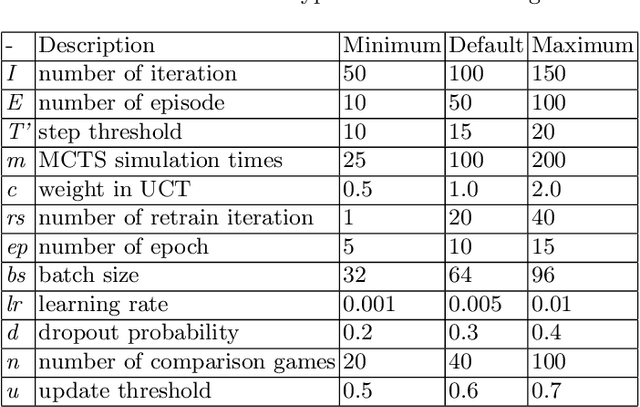
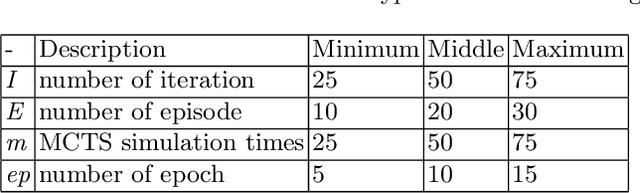
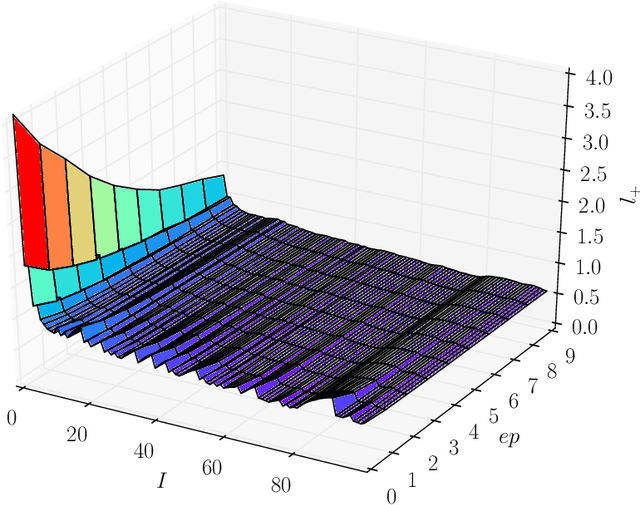
The landmark achievements of AlphaGo Zero have created great research interest into self-play in reinforcement learning. In self-play, Monte Carlo Tree Search is used to train a deep neural network, that is then used in tree searches. Training itself is governed by many hyperparameters.There has been surprisingly little research on design choices for hyper-parameter values and loss-functions, presumably because of the prohibitive computational cost to explore the parameter space. In this paper, we investigate 12 hyper-parameters in an AlphaZero-like self-play algorithm and evaluate how these parameters contribute to training. We use small games, to achieve meaningful exploration with moderate computational effort. The experimental results show that training is highly sensitive to hyper-parameter choices. Through multi-objective analysis we identify 4 important hyper-parameters to further assess. To start, we find surprising results where too much training can sometimes lead to lower performance. Our main result is that the number of self-play iterations subsumes MCTS-search simulations, game-episodes, and training epochs. The intuition is that these three increase together as self-play iterations increase, and that increasing them individually is sub-optimal. A consequence of our experiments is a direct recommendation for setting hyper-parameter values in self-play: the overarching outer-loop of self-play iterations should be maximized, in favor of the three inner-loop hyper-parameters, which should be set at lower values. A secondary result of our experiments concerns the choice of optimization goals, for which we also provide recommendations.