 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of classifiers' robustness to adversarial perturbations
Paper and Code
Mar 28, 2016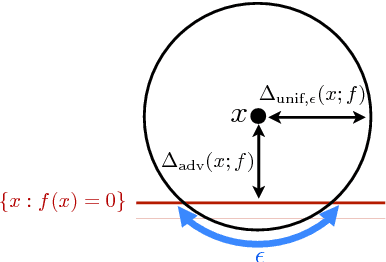


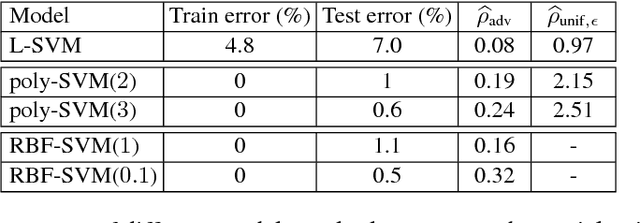
The goal of this paper is to analyze an intriguing phenomenon recently discovered in deep networks, namely their instability to adversarial perturbations (Szegedy et. al., 2014). We provide a theoretical framework for analyzing the robustness of classifiers to adversarial perturbations, and show fundamental upper bounds on the robustness of classifiers. Specifically, we establish a general upper bound on the robustness of classifiers to adversarial perturbations, and then illustrate the obtained upper bound on the families of linear and quadratic classifiers. In both cases, our upper bound depends on a distinguishability measure that captures the notion of difficulty of the classification task. Our results for both classes imply that in tasks involving small distinguishability, no classifier in the considered set will be robust to adversarial perturbations, even if a good accuracy is achieved. Our theoretical framework moreover suggests that the phenomenon of adversarial instability is due to the low flexibility of classifiers, compared to the difficulty of the classification task (captured by the distinguishability). Moreover, we show the existence of a clear distinction between the robustness of a classifier to random noise and its robustness to adversarial perturbations. Specifically, the former is shown to be larger than the latter by a factor that is proportional to \sqrt{d} (with d being the signal dimension) for linear classifiers. This result gives a theoretical explanation for the discrepancy between the two robustness properties in high dimensional problems, which was empirically observed in the context of neural networks. To the best of our knowledge, our results provide the first theoretical work that addresses the phenomenon of adversarial instability recently observed for deep networks. Our analysis is complemented by experimental results on controlled and real-world data.