 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Unsupervised Random Forest Clustering Technique for Automatic Traffic Scenario Categorization
Paper and Code
Apr 05, 2020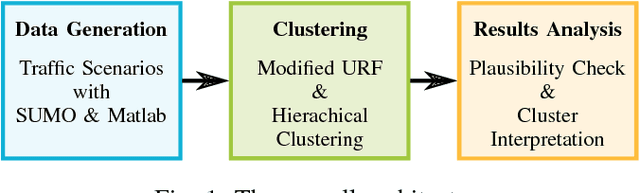

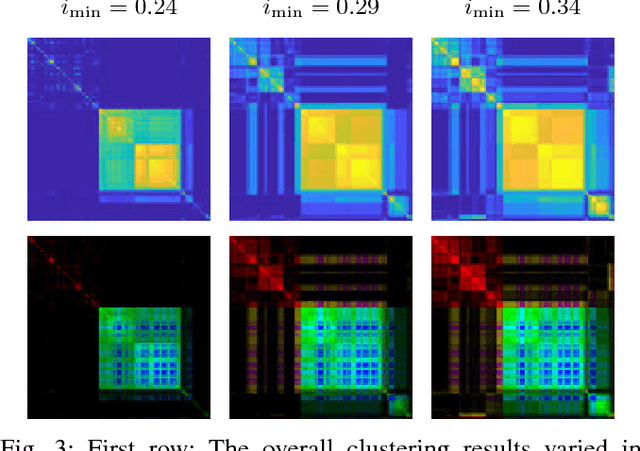
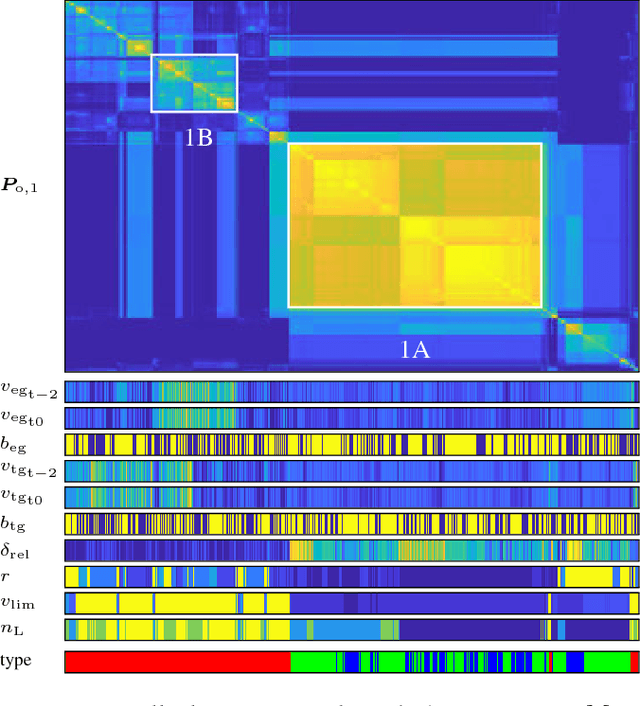
A modification of the Random Forest algorithm for the categorization of traffic situations is introduced in this paper. The procedure yields an unsupervised machine learning method. The algorithm generates a proximity matrix which contains a similarity measure. This matrix is then reordered with hierarchical clustering to achieve a graphically interpretable representation. It is shown how the resulting proximity matrix can be visually interpreted and how the variation of the methods' metaparameter reveals different insights into the data. The proposed method is able to cluster data from any data source. To demonstrate the methods' potential, multiple features derived from a traffic simulation are used in this paper. The knowledge of traffic scenario clusters is crucial to accelerate the validation process. The clue of the method is that scenario templates can be generated automatically from actual traffic situations. These templates can be employed in all stages of the development process. The results prove that the procedure is well suited for an automatic categorization of traffic scenarios. Diverse other applications can benefit from this work.