 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experimental Study of Deep Neural Network Models for Vietnamese Multiple-Choice Reading Comprehension
Paper and Code
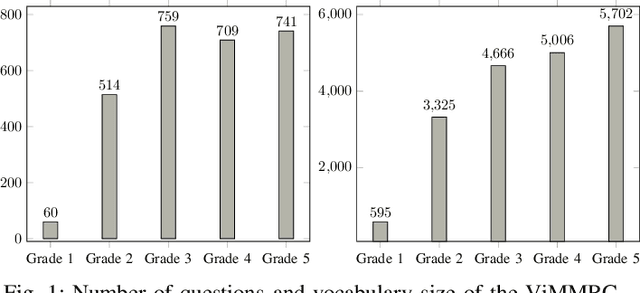
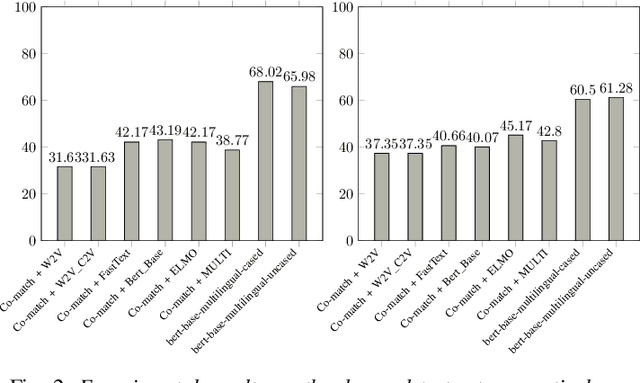

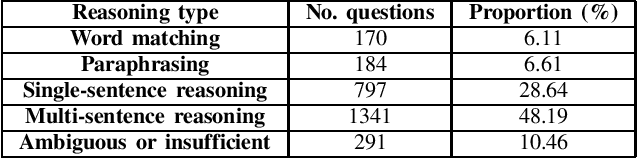
Machine reading comprehension (MRC) is a challenging task in natural language processing that makes computers understanding natural language texts and answer questions based on those texts. There are many techniques for solving this problems, and word representation is a very important technique that impact most to the accuracy of machine reading comprehension problem in the popular languages like English and Chinese. However, few studies on MRC have been conducted in low-resource languages such as Vietnamese. In this paper, we conduct several experiments on neural network-based model to understand the impact of word representation to the Vietnamese multiple-choice machine reading comprehension. Our experiments include using the Co-match model on six different Vietnamese word embeddings and the BERT model for multiple-choice reading comprehension. On the ViMMRC corpus, the accuracy of BERT model is 61.28% on test set.