 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn evaluation of word-level confidence estimation for end-to-end automatic speech recognition
Paper and Code
Jan 14, 2021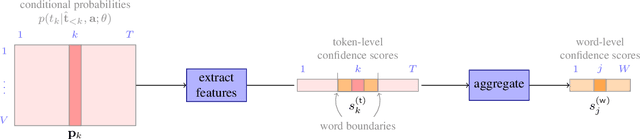
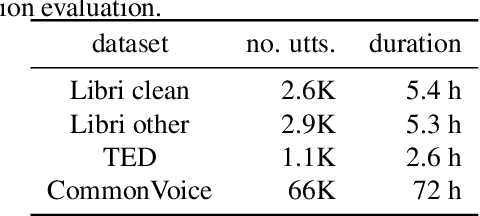
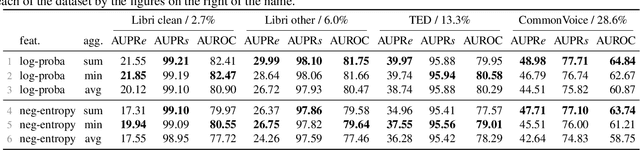
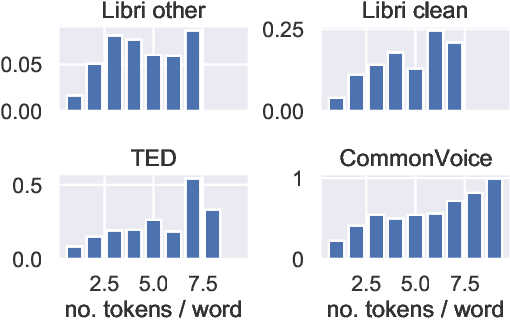
Quantifying the confidence (or conversely the uncertainty) of a prediction is a highly desirable trait of an automatic system, as it improves the robustness and usefulness in downstream tasks. In this paper we investigate confidence estimation for end-to-end automatic speech recognition (ASR). Previous work has addressed confidence measures for lattice-based ASR, while current machine learning research mostly focuses on confidence measures for unstructured deep learning. However, as the ASR systems are increasingly being built upon deep end-to-end methods, there is little work that tries to develop confidence measures in this context. We fill this gap by providing an extensive benchmark of popular confidence methods on four well-known speech datasets. There are two challenges we overcome in adapting existing methods: working on structured data (sequences) and obtaining confidences at a coarser level than the predictions (words instead of tokens). Our results suggest that a strong baseline can be obtained by scaling the logits by a learnt temperature, followed by estimating the confidence as the negative entropy of the predictive distribution and, finally, sum pooling to aggregate at word level.