 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn enriched category theory of language: from syntax to semantics
Paper and Code
Jun 15, 2021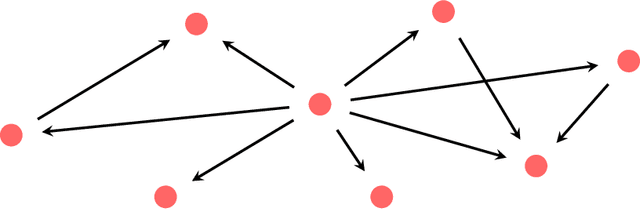
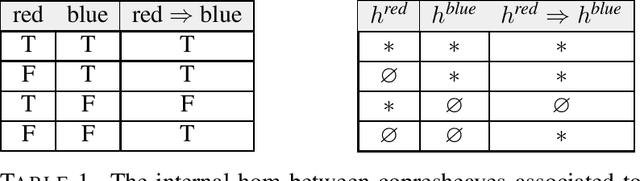
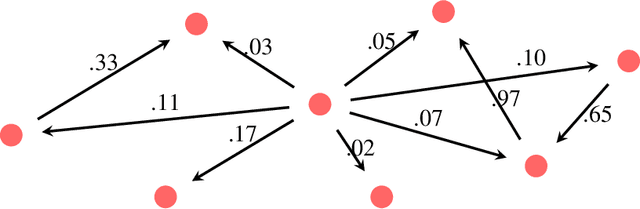
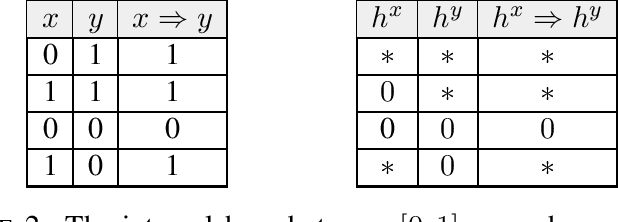
Given a piece of text, the ability to generate a coherent extension of it implies some sophistication, including a knowledge of grammar and semantics. In this paper, we propose a mathematical framework for passing from probability distributions on extensions of given texts to an enriched category containing semantic information. Roughly speaking, we model probability distributions on texts as a category enriched over the unit interval. Objects of this category are expressions in language and hom objects are conditional probabilities that one expression is an extension of another. This category is syntactical: it describes what goes with what. We then pass to the enriched category of unit interval-valued copresheaves on this syntactical category to find semantic information.