 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Speech Summarization Using Large Language Model
Paper and Code
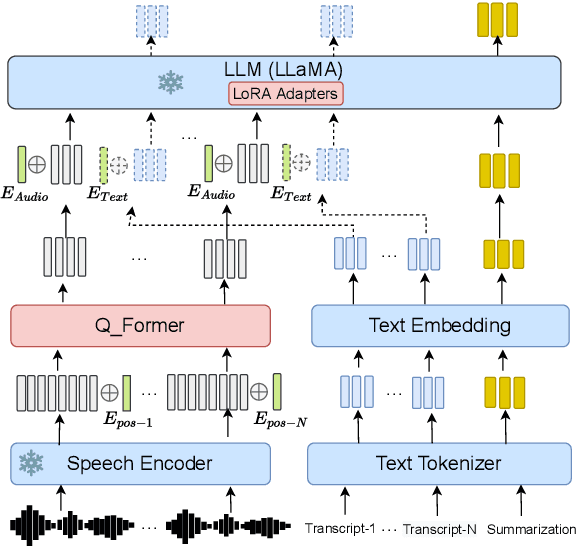

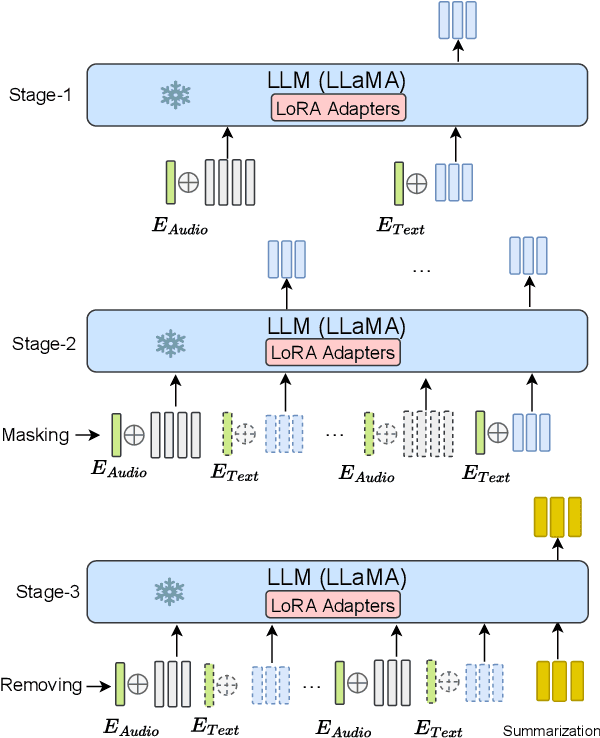

Abstractive Speech Summarization (SSum) aims to generate human-like text summaries from spoken content. It encounters difficulties in handling long speech input and capturing the intricate cross-modal mapping between long speech inputs and short text summaries. Research on large language models (LLMs) and multimodal information fusion has provided new insights for addressing these challenges. In this paper, we propose an end-to-end SSum model that utilizes Q-Former as a connector for the audio-text modality and employs LLMs to generate text summaries directly from speech features. We adopt a multi-stage training approach that includes LLM based ASR and Text Summarization (TSum) tasks as auxiliary tasks. ASR tasks are used to align feature spaces and enhance the LLM's ability to handle longer speech. Then, we utilize a curriculum learning strategy to facilitate the model's transition from TSum to SSum. Finally, our model achieves competitive performance on the How-2 dataset.