 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Neural Keyphrase Generation
Paper and Code

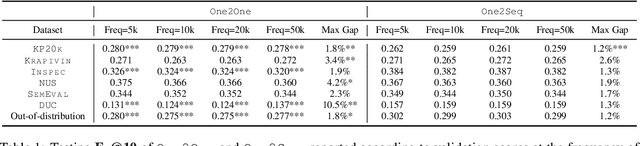

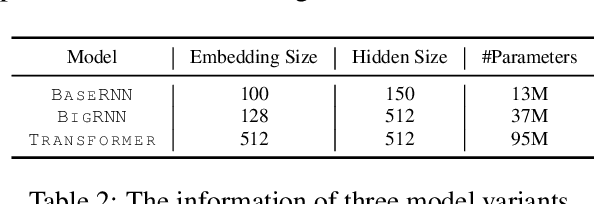
Recent years have seen a flourishing of neural keyphrase generation works, including the release of several large-scale datasets and a host of new models to tackle them. Model performance on keyphrase generation tasks has increased significantly with evolving deep learning research. However, there lacks a comprehensive comparison among models, and an investigation on related factors (e.g., architectural choice, decoding strategy) that may affect a keyphrase generation system's performance. In this empirical study, we aim to fill this gap by providing extensive experimental results and analyzing the most crucial factors impacting the performance of keyphrase generation models. We hope this study can help clarify some of the uncertainties surrounding the keyphrase generation task and facilitate future research on this topic.