 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn analytic formulation for positive-unlabeled learning via weighted integral probability metric
Paper and Code
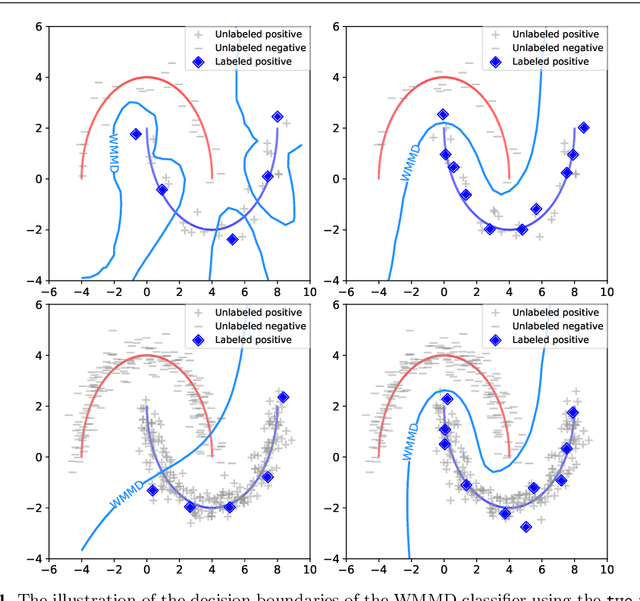


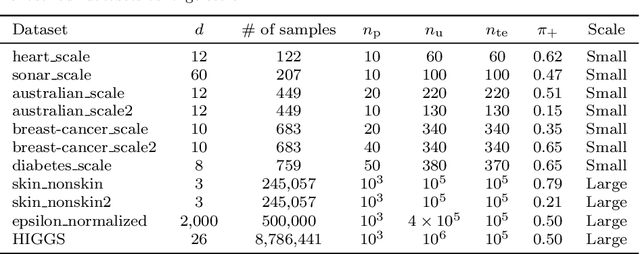
We consider the problem of learning a binary classifier from only positive and unlabeled observations (PU learning). Although recent research in PU learning has succeeded in showing theoretical and empirical performance, most existing algorithms need to solve either a convex or a non-convex optimization problem and thus are not suitable for large-scale datasets. In this paper, we propose a simple yet theoretically grounded PU learning algorithm by extending the previous work proposed for supervised binary classification (Sriperumbudur et al., 2012). The proposed PU learning algorithm produces a closed-form classifier when the hypothesis space is a closed ball in reproducing kernel Hilbert space. In addition, we establish upper bounds of the estimation error and the excess risk. The obtained estimation error bound is sharper than existing results and the excess risk bound does not rely on an approximation error term. To the best of our knowledge, we are the first to explicitly derive the excess risk bound in the field of PU learning. Finally, we conduct extensive numerical experiments using both synthetic and real datasets, demonstrating improved accuracy, scalability, and robustness of the proposed algorithm.