 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn adaptive nearest neighbor rule for classification
Paper and Code
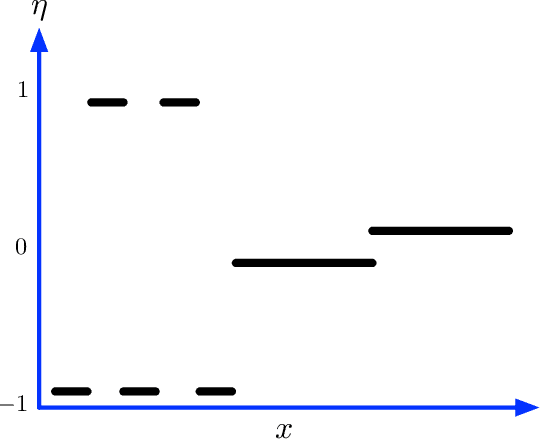

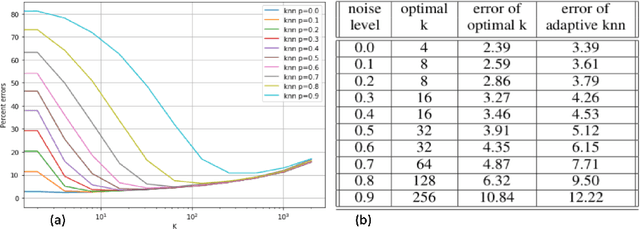
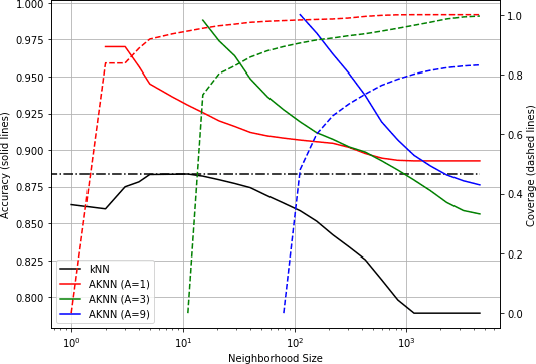
We introduce a variant of the $k$-nearest neighbor classifier in which $k$ is chosen adaptively for each query, rather than supplied as a parameter. The choice of $k$ depends on properties of each neighborhood, and therefore may significantly vary between different points. (For example, the algorithm will use larger $k$ for predicting the labels of points in noisy regions.) We provide theory and experiments that demonstrate that the algorithm performs comparably to, and sometimes better than, $k$-NN with an optimal choice of $k$. In particular, we derive bounds on the convergence rates of our classifier that depend on a local quantity we call the `advantage' which is significantly weaker than the Lipschitz conditions used in previous convergence rate proofs. These generalization bounds hinge on a variant of the seminal Uniform Convergence Theorem due to Vapnik and Chervonenkis; this variant concerns conditional probabilities and may be of independent interest.