 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMaze: An intuitive benchmark generator for fast prototyping of generalizable agents
Paper and Code
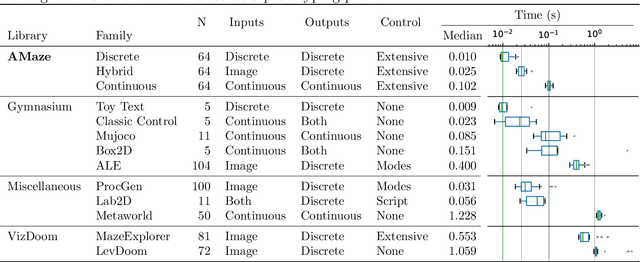
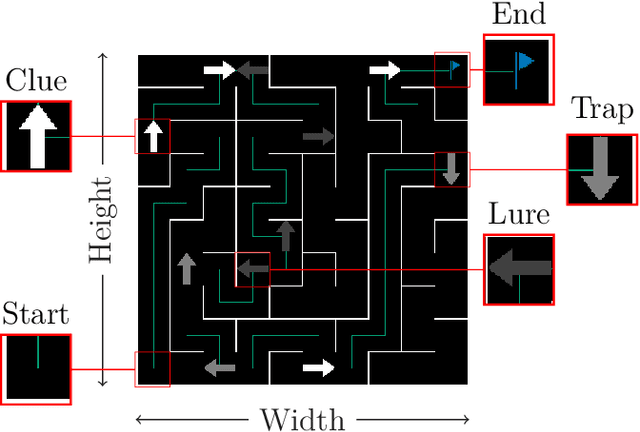
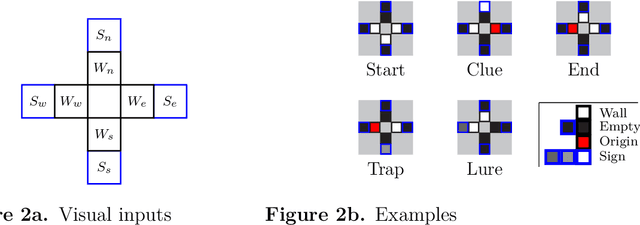
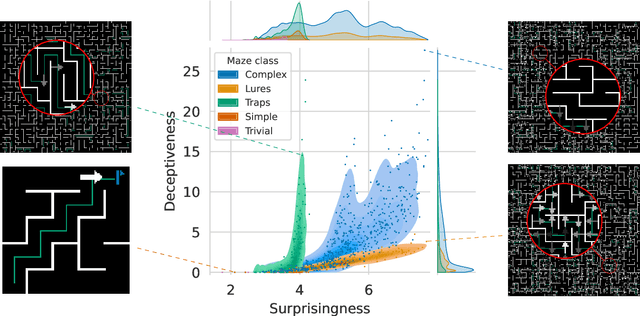
Traditional approaches to training agents have generally involved a single, deterministic environment of minimal complexity to solve various tasks such as robot locomotion or computer vision. However, agents trained in static environments lack generalization capabilities, limiting their potential in broader scenarios. Thus, recent benchmarks frequently rely on multiple environments, for instance, by providing stochastic noise, simple permutations, or altogether different settings. In practice, such collections result mainly from costly human-designed processes or the liberal use of random number generators. In this work, we introduce AMaze, a novel benchmark generator in which embodied agents must navigate a maze by interpreting visual signs of arbitrary complexities and deceptiveness. This generator promotes human interaction through the easy generation of feature-specific mazes and an intuitive understanding of the resulting agents' strategies. As a proof-of-concept, we demonstrate the capabilities of the generator in a simple, fully discrete case with limited deceptiveness. Agents were trained under three different regimes (one-shot, scaffolding, interactive), and the results showed that the latter two cases outperform direct training in terms of generalization capabilities. Indeed, depending on the combination of generalization metric, training regime, and algorithm, the median gain ranged from 50% to 100% and maximal performance was achieved through interactive training, thereby demonstrating the benefits of a controllable human-in-the-loop benchmark generator.