 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-free HDR Deghosting with Semantics Consistent Transformer
Paper and Code
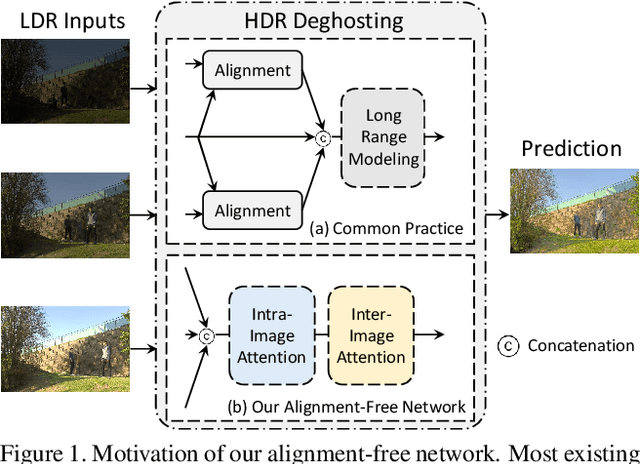
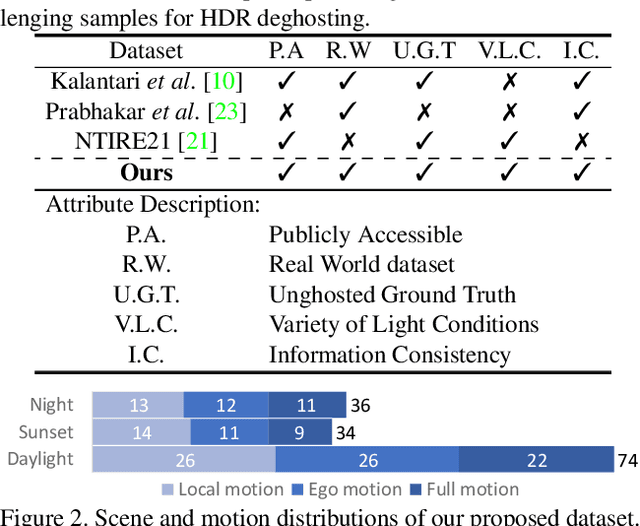
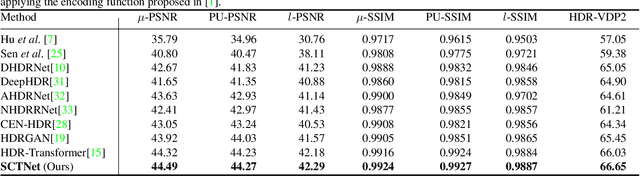

High dynamic range (HDR) imaging aims to retrieve information from multiple low-dynamic range inputs to generate realistic output. The essence is to leverage the contextual information, including both dynamic and static semantics, for better image generation. Existing methods often focus on the spatial misalignment across input frames caused by the foreground and/or camera motion. However, there is no research on jointly leveraging the dynamic and static context in a simultaneous manner. To delve into this problem, we propose a novel alignment-free network with a Semantics Consistent Transformer (SCTNet) with both spatial and channel attention modules in the network. The spatial attention aims to deal with the intra-image correlation to model the dynamic motion, while the channel attention enables the inter-image intertwining to enhance the semantic consistency across frames. Aside from this, we introduce a novel realistic HDR dataset with more variations in foreground objects, environmental factors, and larger motions. Extensive comparisons on both conventional datasets and ours validate the effectiveness of our method, achieving the best trade-off on the performance and the computational cost.