 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Regularization in Model-free Overparametrized Asymmetric Matrix Factorization
Paper and Code
Mar 06, 2022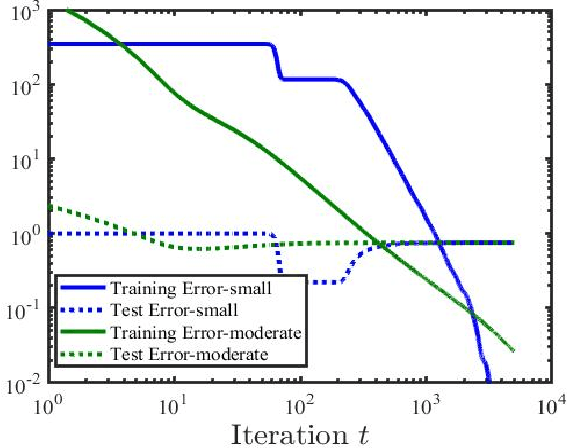
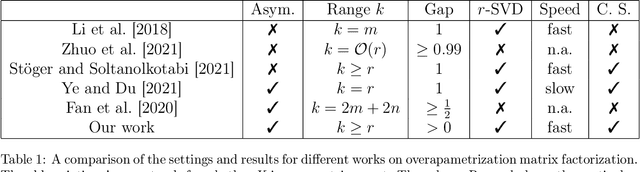
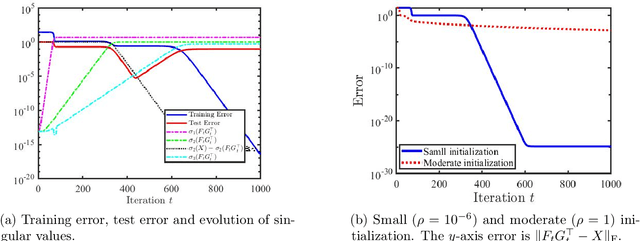
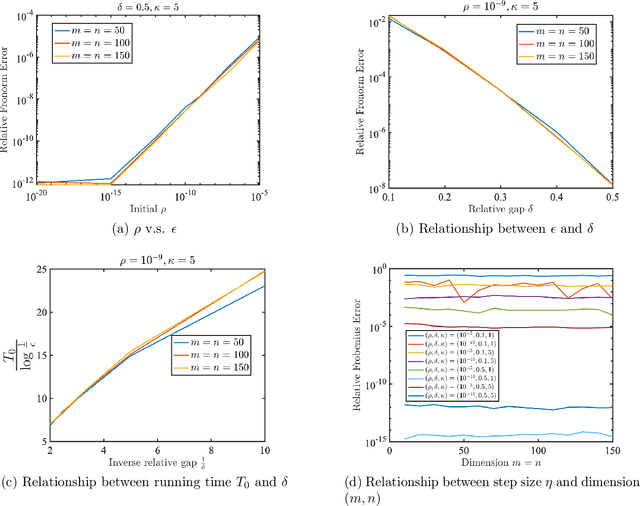
We study the asymmetric matrix factorization problem under a natural nonconvex formulation with arbitrary overparamatrization. We consider the model-free setting with no further assumption on the rank or singular values of the observed matrix, where the global optima provably overfit. We show that vanilla gradient descent with small random initialization and early stopping produces the best low-rank approximation of the observed matrix, without any additional regularization. We provide a sharp analysis on relationship between the iteration complexity, initialization size, stepsize and final error. In particular, our complexity bound is almost dimension-free and depends logarithmically on the final error, and our results have lenient requirements on the stepsize and initialization. Our bounds improve upon existing work and show good agreement with numerical experiments.